mirror of
https://github.com/open-compass/opencompass.git
synced 2025-05-30 16:03:24 +08:00
[Feature] Add Arc Prize Public Evaluation (#1690)
* support arc prize * update arc-prize dataset info & update arc-prize evaluation performance
This commit is contained in:
parent
bcb707dbfc
commit
f7dbe6bb7d
@ -0,0 +1,47 @@
|
||||
# ARC Prize Public Evaluation
|
||||
|
||||
#### Overview
|
||||
The spirit of ARC Prize is to open source progress towards AGI. To win prize money, you will be required to publish reproducible code/methods into public domain.
|
||||
|
||||
ARC Prize measures AGI progress using the [ARC-AGI private evaluation set](https://arcprize.org/guide#private), [the leaderboard is here](https://arcprize.org/leaderboard), and the Grand Prize is unlocked once the first team reaches [at least 85%](https://arcprize.org/guide#grand-prize-goal).
|
||||
|
||||
Note: the private evaluation set imposes limitations on solutions (eg. no internet access, so no GPT-4/Claude/etc). There is a [secondary leaderboard](https://arcprize.org/leaderboard) called ARC-AGI-Pub, it measures the [public evaluation set](https://arcprize.org/guide#public-tasks) and imposes no limits but it is not part of ARC Prize 2024 at this time.
|
||||
|
||||
|
||||
#### Tasks
|
||||
ARC-AGI tasks are a series of three to five input and output tasks followed by a final task with only the input listed. Each task tests the utilization of a specific learned skill based on a minimal number of cognitive priors.
|
||||
|
||||
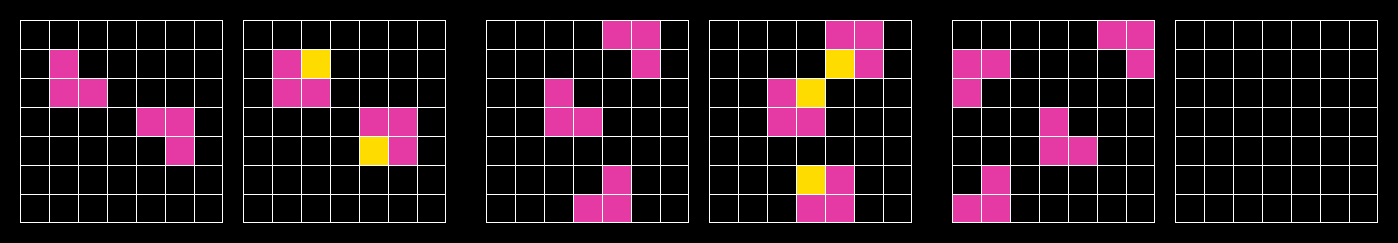
|
||||
|
||||
Tasks are represented as JSON lists of integers. These JSON objects can also be represented visually as a grid of colors using an ARC-AGI task viewer.
|
||||
|
||||
A successful submission is a pixel-perfect description (color and position) of the final task's output.
|
||||
|
||||
#### Format
|
||||
|
||||
As mentioned above, tasks are stored in JSON format. Each JSON file consists of two key-value pairs.
|
||||
|
||||
`train`: a list of two to ten input/output pairs (typically three.) These are used for your algorithm to infer a rule.
|
||||
|
||||
`test`: a list of one to three input/output pairs (typically one.) Your model should apply the inferred rule from the train set and construct an output solution. You will have access to the output test solution on the public data. The output solution on the private evaluation set will not be revealed.
|
||||
|
||||
Here is an example of a simple ARC-AGI task that has three training pairs along with a single test pair. Each pair is shown as a 2x2 grid. There are four colors represented by the integers 1, 4, 6, and 8. Which actual color (red/green/blue/black) is applied to each integer is arbitrary and up to you.
|
||||
|
||||
```json
|
||||
{
|
||||
"train": [
|
||||
{"input": [[1, 0], [0, 0]], "output": [[1, 1], [1, 1]]},
|
||||
{"input": [[0, 0], [4, 0]], "output": [[4, 4], [4, 4]]},
|
||||
{"input": [[0, 0], [6, 0]], "output": [[6, 6], [6, 6]]}
|
||||
],
|
||||
"test": [
|
||||
{"input": [[0, 0], [0, 8]], "output": [[8, 8], [8, 8]]}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
#### Performance
|
||||
|
||||
| Qwen2.5-72B-Instruct | LLaMA3.1-70B-Instruct | gemma-2-27b-it |
|
||||
| ----- | ----- | ----- |
|
||||
| 0.09 | 0.06 | 0.05 |
|
||||
@ -0,0 +1,4 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .arc_prize_public_evaluation_gen_872059 import arc_prize_public_evaluation_datasets # noqa: F401, F403
|
||||
@ -0,0 +1,56 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets.arc_prize_public_evaluation import ARCPrizeDataset, ARCPrizeEvaluator
|
||||
|
||||
|
||||
# The system_prompt defines the initial instructions for the model,
|
||||
# setting the context for solving ARC tasks.
|
||||
system_prompt = '''You are a puzzle solving wizard. You are given a puzzle from the abstraction and reasoning corpus developed by Francois Chollet.'''
|
||||
|
||||
# User message template is a template for creating user prompts. It includes placeholders for training data and test input data,
|
||||
# guiding the model to learn the rule and apply it to solve the given puzzle.
|
||||
user_message_template = '''Here are the example input and output pairs from which you should learn the underlying rule to later predict the output for the given test input:
|
||||
----------------------------------------
|
||||
{training_data}
|
||||
----------------------------------------
|
||||
Now, solve the following puzzle based on its input grid by applying the rules you have learned from the training data.:
|
||||
----------------------------------------
|
||||
[{{'input': {input_test_data}, 'output': [[]]}}]
|
||||
----------------------------------------
|
||||
What is the output grid? Only provide the output grid in the form as in the example input and output pairs. Do not provide any additional information:'''
|
||||
|
||||
|
||||
arc_prize_public_evaluation_reader_cfg = dict(
|
||||
input_columns=['training_data', 'input_test_data'],
|
||||
output_column='output_test_data'
|
||||
)
|
||||
|
||||
arc_prize_public_evaluation_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(role='SYSTEM', prompt=system_prompt),
|
||||
dict(role='HUMAN', prompt=user_message_template),
|
||||
],
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=2048)
|
||||
)
|
||||
|
||||
arc_prize_public_evaluation_eval_cfg = dict(
|
||||
evaluator=dict(type=ARCPrizeEvaluator)
|
||||
)
|
||||
|
||||
arc_prize_public_evaluation_datasets = [
|
||||
dict(
|
||||
abbr='ARC_Prize_Public_Evaluation',
|
||||
type=ARCPrizeDataset,
|
||||
path='opencompass/arc_prize_public_evaluation',
|
||||
reader_cfg=arc_prize_public_evaluation_reader_cfg,
|
||||
infer_cfg=arc_prize_public_evaluation_infer_cfg,
|
||||
eval_cfg=arc_prize_public_evaluation_eval_cfg
|
||||
)
|
||||
]
|
||||
213
opencompass/datasets/arc_prize_public_evaluation.py
Normal file
213
opencompass/datasets/arc_prize_public_evaluation.py
Normal file
@ -0,0 +1,213 @@
|
||||
import ast
|
||||
import json
|
||||
import os
|
||||
from typing import Dict, List
|
||||
|
||||
import numpy as np
|
||||
from datasets import Dataset
|
||||
|
||||
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
||||
from opencompass.registry import LOAD_DATASET
|
||||
from opencompass.utils import get_data_path
|
||||
|
||||
from .base import BaseDataset
|
||||
|
||||
|
||||
@LOAD_DATASET.register_module()
|
||||
class ARCPrizeDataset(BaseDataset):
|
||||
task_file_names = [
|
||||
'2072aba6.json', 'bb52a14b.json', '136b0064.json', 'ea9794b1.json',
|
||||
'40f6cd08.json', 'f5aa3634.json', '7039b2d7.json', '712bf12e.json',
|
||||
'9b365c51.json', 'ccd554ac.json', 'f9d67f8b.json', '03560426.json',
|
||||
'e2092e0c.json', '8fbca751.json', '42918530.json', 'c64f1187.json',
|
||||
'00576224.json', '705a3229.json', 'af24b4cc.json', '81c0276b.json',
|
||||
'f21745ec.json', '8dae5dfc.json', '4e469f39.json', '695367ec.json',
|
||||
'dc2aa30b.json', 'b9630600.json', '770cc55f.json', '3391f8c0.json',
|
||||
'c1990cce.json', '1da012fc.json', '50a16a69.json', '212895b5.json',
|
||||
'e69241bd.json', '692cd3b6.json', '0bb8deee.json', '9772c176.json',
|
||||
'22a4bbc2.json', 'ca8de6ea.json', 'dc2e9a9d.json', '4aab4007.json',
|
||||
'cfb2ce5a.json', '9f27f097.json', '2c737e39.json', '84db8fc4.json',
|
||||
'e1baa8a4.json', 'ea959feb.json', '4f537728.json', '47996f11.json',
|
||||
'bf32578f.json', 'aee291af.json', '5d2a5c43.json', '2546ccf6.json',
|
||||
'e57337a4.json', 'd4b1c2b1.json', '20981f0e.json', '05a7bcf2.json',
|
||||
'fc754716.json', '6ad5bdfd.json', 'e88171ec.json', '1acc24af.json',
|
||||
'34b99a2b.json', 'e78887d1.json', '4acc7107.json', '137f0df0.json',
|
||||
'62b74c02.json', '50aad11f.json', '642d658d.json', '64a7c07e.json',
|
||||
'bd14c3bf.json', '73c3b0d8.json', 'e0fb7511.json', 'c7d4e6ad.json',
|
||||
'85b81ff1.json', 'e760a62e.json', 'ca8f78db.json', 'd931c21c.json',
|
||||
'aab50785.json', 'ac605cbb.json', '3194b014.json', '68b67ca3.json',
|
||||
'e7b06bea.json', 'e5790162.json', 'da2b0fe3.json', '0becf7df.json',
|
||||
'fe9372f3.json', 'd56f2372.json', 'e66aafb8.json', 'b7999b51.json',
|
||||
'2697da3f.json', '516b51b7.json', '9a4bb226.json', '195ba7dc.json',
|
||||
'310f3251.json', '639f5a19.json', '0d87d2a6.json', 'c663677b.json',
|
||||
'e74e1818.json', '69889d6e.json', 'f45f5ca7.json', '8597cfd7.json',
|
||||
'0c9aba6e.json', 'e9b4f6fc.json', 'e7639916.json', '5207a7b5.json',
|
||||
'e4075551.json', '90347967.json', '9ddd00f0.json', '4b6b68e5.json',
|
||||
'e9c9d9a1.json', '2f0c5170.json', '58e15b12.json', 'd37a1ef5.json',
|
||||
'62ab2642.json', 'b457fec5.json', 'c97c0139.json', 'ac0c5833.json',
|
||||
'7d419a02.json', '4ff4c9da.json', '4cd1b7b2.json', '27a77e38.json',
|
||||
'66f2d22f.json', '2a5f8217.json', 'c074846d.json', 'c6e1b8da.json',
|
||||
'319f2597.json', '94be5b80.json', '55783887.json', '60c09cac.json',
|
||||
'f823c43c.json', 'd492a647.json', 'e681b708.json', '15663ba9.json',
|
||||
'a3f84088.json', '103eff5b.json', '5a5a2103.json', '1e97544e.json',
|
||||
'009d5c81.json', 'ed74f2f2.json', 'ce039d91.json', 'baf41dbf.json',
|
||||
'3490cc26.json', 'ce8d95cc.json', '3f23242b.json', '1d0a4b61.json',
|
||||
'8719f442.json', 'd94c3b52.json', '4c177718.json', '59341089.json',
|
||||
'3ee1011a.json', 'f5c89df1.json', '5833af48.json', 'd4c90558.json',
|
||||
'88207623.json', '833dafe3.json', '070dd51e.json', '3ed85e70.json',
|
||||
'21f83797.json', '7c8af763.json', '5783df64.json', 'a57f2f04.json',
|
||||
'e9ac8c9e.json', 'aa18de87.json', '505fff84.json', '5ffb2104.json',
|
||||
'42a15761.json', '1a2e2828.json', '0607ce86.json', '84f2aca1.json',
|
||||
'456873bc.json', '903d1b4a.json', '0f63c0b9.json', '54db823b.json',
|
||||
'ad7e01d0.json', '8e2edd66.json', '79fb03f4.json', '4364c1c4.json',
|
||||
'e7a25a18.json', 'e133d23d.json', 'e21a174a.json', '55059096.json',
|
||||
'e95e3d8e.json', '94414823.json', '9356391f.json', '15113be4.json',
|
||||
'ba9d41b8.json', '52fd389e.json', 'de493100.json', '9c56f360.json',
|
||||
'c92b942c.json', '97239e3d.json', 'b0f4d537.json', '19bb5feb.json',
|
||||
'506d28a5.json', '5b692c0f.json', 'ef26cbf6.json', 'e345f17b.json',
|
||||
'7d1f7ee8.json', 'ac3e2b04.json', '551d5bf1.json', 'fb791726.json',
|
||||
'2037f2c7.json', 'e6de6e8f.json', '3d31c5b3.json', 'd19f7514.json',
|
||||
'1d398264.json', '358ba94e.json', '696d4842.json', '08573cc6.json',
|
||||
'7e02026e.json', '7953d61e.json', 'c3202e5a.json', '351d6448.json',
|
||||
'fea12743.json', '12422b43.json', 'b942fd60.json', 'bcb3040b.json',
|
||||
'e41c6fd3.json', 'a59b95c0.json', '3a301edc.json', '0b17323b.json',
|
||||
'da515329.json', '96a8c0cd.json', '6f473927.json', '9def23fe.json',
|
||||
'c35c1b4c.json', 'be03b35f.json', '604001fa.json', 'd304284e.json',
|
||||
'cb227835.json', 'e9bb6954.json', 'ac2e8ecf.json', '1e81d6f9.json',
|
||||
'72207abc.json', '37d3e8b2.json', 'c8b7cc0f.json', 'a096bf4d.json',
|
||||
'1c02dbbe.json', 'fd096ab6.json', '9bebae7a.json', '25094a63.json',
|
||||
'b7fb29bc.json', 'aa4ec2a5.json', '50f325b5.json', '423a55dc.json',
|
||||
'b0722778.json', 'e7dd8335.json', 'f3cdc58f.json', 'cad67732.json',
|
||||
'256b0a75.json', 'd282b262.json', '58743b76.json', '6df30ad6.json',
|
||||
'9110e3c5.json', '48f8583b.json', 'a680ac02.json', '642248e4.json',
|
||||
'2685904e.json', '48131b3c.json', 'b7cb93ac.json', '73182012.json',
|
||||
'df8cc377.json', '3b4c2228.json', '93c31fbe.json', '8ee62060.json',
|
||||
'9b2a60aa.json', 'f0df5ff0.json', '917bccba.json', 'ed98d772.json',
|
||||
'bf89d739.json', 'f3e62deb.json', '11e1fe23.json', 'bbb1b8b6.json',
|
||||
'f4081712.json', '817e6c09.json', '45bbe264.json', 'f3b10344.json',
|
||||
'fafd9572.json', 'b7f8a4d8.json', '2c0b0aff.json', '8cb8642d.json',
|
||||
'67c52801.json', 'd47aa2ff.json', '0934a4d8.json', '60a26a3e.json',
|
||||
'cf133acc.json', '5289ad53.json', '16b78196.json', '09c534e7.json',
|
||||
'f83cb3f6.json', 'd017b73f.json', 'b20f7c8b.json', '5af49b42.json',
|
||||
'18419cfa.json', '929ab4e9.json', '6a11f6da.json', '17cae0c1.json',
|
||||
'e99362f0.json', '1c56ad9f.json', '8a371977.json', 'e633a9e5.json',
|
||||
'c658a4bd.json', 'bc4146bd.json', '67636eac.json', '4e45f183.json',
|
||||
'17b80ad2.json', '94133066.json', 'e1d2900e.json', 'a934301b.json',
|
||||
'0a2355a6.json', '45737921.json', '332efdb3.json', '7bb29440.json',
|
||||
'f9a67cb5.json', 'a8610ef7.json', '32e9702f.json', '0c786b71.json',
|
||||
'626c0bcc.json', 'aa300dc3.json', 'c62e2108.json', '0692e18c.json',
|
||||
'af22c60d.json', '992798f6.json', 'c48954c1.json', '5b526a93.json',
|
||||
'ae58858e.json', 'ff72ca3e.json', '2b01abd0.json', '7d18a6fb.json',
|
||||
'963f59bc.json', '759f3fd3.json', '7c9b52a0.json', '4852f2fa.json',
|
||||
'14754a24.json', 'c87289bb.json', '845d6e51.json', '281123b4.json',
|
||||
'79369cc6.json', '0a1d4ef5.json', '477d2879.json', '72a961c9.json',
|
||||
'67b4a34d.json', 'e5c44e8f.json', 'bf699163.json', '13713586.json',
|
||||
'27f8ce4f.json', '95a58926.json', '15696249.json', 'd2acf2cb.json',
|
||||
'140c817e.json', '1990f7a8.json', '782b5218.json', '8b28cd80.json',
|
||||
'92e50de0.json', 'e619ca6e.json', '5b6cbef5.json', '575b1a71.json',
|
||||
'66e6c45b.json', '31adaf00.json', '6ea4a07e.json', 'f0afb749.json',
|
||||
'00dbd492.json', 'b1fc8b8e.json', 'fd4b2b02.json', 'b15fca0b.json',
|
||||
'a04b2602.json', '20818e16.json', '762cd429.json', '29700607.json',
|
||||
'd5c634a2.json', 'a406ac07.json', '8ba14f53.json', '184a9768.json',
|
||||
'12997ef3.json', 'dd2401ed.json', 'f8be4b64.json', '12eac192.json',
|
||||
'31d5ba1a.json', 'b4a43f3b.json', '7ee1c6ea.json', '9b4c17c4.json',
|
||||
'981571dc.json', '93b4f4b3.json', '9caba7c3.json', '891232d6.json',
|
||||
'85fa5666.json', '0e671a1a.json', '73ccf9c2.json', '414297c0.json',
|
||||
'e872b94a.json', '99306f82.json', '3979b1a8.json', '2753e76c.json',
|
||||
'1c0d0a4b.json', '292dd178.json', 'cd3c21df.json', '33b52de3.json',
|
||||
'ecaa0ec1.json', '896d5239.json', '1a6449f1.json', '9c1e755f.json'
|
||||
]
|
||||
|
||||
@staticmethod
|
||||
def load(path: str):
|
||||
task_file_dir = get_data_path(path)
|
||||
|
||||
dataset = []
|
||||
|
||||
task_file_name_list = os.listdir(task_file_dir)
|
||||
for task_file_name in task_file_name_list:
|
||||
if task_file_name not in ARCPrizeDataset.task_file_names:
|
||||
continue
|
||||
with open(os.path.join(task_file_dir, task_file_name),
|
||||
'r') as file:
|
||||
task = json.load(file)
|
||||
task = {
|
||||
'training_data': task['train'],
|
||||
'input_test_data': task['test'][0]['input'],
|
||||
'output_test_data': task['test'][0]['output']
|
||||
}
|
||||
dataset.append(task)
|
||||
|
||||
return Dataset.from_list(dataset)
|
||||
|
||||
|
||||
class ARCPrizeEvaluator(BaseEvaluator):
|
||||
|
||||
def score(self, predictions: List[str],
|
||||
references: List[List[int]]) -> Dict:
|
||||
accuracy = []
|
||||
details = []
|
||||
for pred, refer in zip(map(extract_solution, predictions), references):
|
||||
is_correct, correct_percentage = compare_solutions_with_padding(
|
||||
pred, refer, pad_value=-1)
|
||||
details.append({
|
||||
'solved': True if is_correct else False,
|
||||
'correct_percentage': correct_percentage,
|
||||
'generated_solution': pred
|
||||
})
|
||||
accuracy.append(1 if is_correct else 0)
|
||||
|
||||
return {'accuracy': np.mean(accuracy), 'details': details}
|
||||
|
||||
|
||||
def extract_solution(text):
|
||||
try:
|
||||
# Find the part of the text that looks like a nested list
|
||||
start = text.index('[[')
|
||||
end = text.index(']]', start) + 2
|
||||
array_str = text[start:end]
|
||||
|
||||
# Use ast.literal_eval to safely evaluate the
|
||||
# string as a Python expression
|
||||
array = ast.literal_eval(array_str)
|
||||
# Check if the result is a list of lists
|
||||
if all(isinstance(i, list) for i in array):
|
||||
if all(all(isinstance(i, int) for i in j) for j in array):
|
||||
return array
|
||||
else:
|
||||
return [[0]]
|
||||
else:
|
||||
return [[0]]
|
||||
except (ValueError, SyntaxError):
|
||||
return [[0]]
|
||||
|
||||
|
||||
def pad_array_with_value(array, target_shape, pad_value):
|
||||
padded_array = np.full(target_shape, pad_value, dtype=int)
|
||||
for i in range(len(array)):
|
||||
padded_array[i, :len(array[i])] = array[i]
|
||||
return padded_array
|
||||
|
||||
|
||||
def compare_solutions_with_padding(generated_output: List[int],
|
||||
correct_output: List[int],
|
||||
pad_value=-1):
|
||||
max_rows = max(len(generated_output), len(correct_output))
|
||||
max_cols = max(max(map(len, generated_output)),
|
||||
max(map(len, correct_output)))
|
||||
target_shape = (max_rows, max_cols)
|
||||
|
||||
padded_generated = pad_array_with_value(generated_output, target_shape,
|
||||
pad_value)
|
||||
padded_correct = pad_array_with_value(correct_output, target_shape,
|
||||
pad_value)
|
||||
|
||||
total_pixels = max_rows * max_cols
|
||||
correct_pixels = np.sum((padded_generated == padded_correct)
|
||||
& (padded_generated != pad_value)
|
||||
& (padded_correct != pad_value))
|
||||
correct_percentage = (correct_pixels / total_pixels) * 100
|
||||
|
||||
is_correct = (correct_pixels == total_pixels)
|
||||
|
||||
return is_correct, correct_percentage
|
||||
@ -343,6 +343,11 @@ DATASETS_MAPPING = {
|
||||
"hf_id": "",
|
||||
"local": "./data/babilong/data/",
|
||||
},
|
||||
"opencompass/arc_prize_public_evaluation": {
|
||||
"ms_id": "",
|
||||
"hf_id": "",
|
||||
"local": "./data/arc_prize_public_evaluation",
|
||||
}
|
||||
}
|
||||
|
||||
DATASETS_URL = {
|
||||
@ -557,5 +562,9 @@ DATASETS_URL = {
|
||||
"subjective/judgerbench": {
|
||||
"url": "http://opencompass.oss-cn-shanghai.aliyuncs.com/datasets/data/judgerbench.zip",
|
||||
"md5": "60d605883aa8cac9755819140ab42c6b"
|
||||
},
|
||||
"/arc_prize_public_evaluation": {
|
||||
"url": "http://opencompass.oss-cn-shanghai.aliyuncs.com/datasets/data/arc_prize_public_evaluation.zip",
|
||||
"md5": "367a33977651496efddba7670009807e"
|
||||
}
|
||||
}
|
||||
|
||||
Loading…
Reference in New Issue
Block a user