mirror of
https://github.com/open-compass/opencompass.git
synced 2025-05-30 16:03:24 +08:00
Merge branch 'open-compass:main' into main
This commit is contained in:
commit
97c1531ed4
@ -22,7 +22,7 @@ with read_base():
|
||||
from opencompass.configs.datasets.gpqa.gpqa_openai_simple_evals_gen_5aeece import \
|
||||
gpqa_datasets # noqa: F401, E501
|
||||
# new datasets in Fullbench v1.1
|
||||
from opencompass.configs.datasets.gsm8k.gsm8k_0shot_v2_gen_a58960 import \
|
||||
from opencompass.configs.datasets.gsm8k.gsm8k_0shot_v2_gen_6e39a4 import \
|
||||
gsm8k_datasets # noqa: F401, E501
|
||||
from opencompass.configs.datasets.hellaswag.hellaswag_10shot_gen_e42710 import \
|
||||
hellaswag_datasets # noqa: F401, E501
|
||||
@ -46,7 +46,7 @@ with read_base():
|
||||
mmlu_pro_datasets # noqa: F401, E501
|
||||
from opencompass.configs.datasets.mmmlu_lite.mmmlu_lite_gen_c51a84 import \
|
||||
mmmlu_lite_datasets # noqa: F401, E501
|
||||
from opencompass.configs.datasets.musr.musr_gen_3c6e15 import \
|
||||
from opencompass.configs.datasets.musr.musr_gen_3622bb import \
|
||||
musr_datasets # noqa: F401, E501
|
||||
from opencompass.configs.datasets.nq.nq_open_1shot_gen_2e45e5 import \
|
||||
nq_datasets # noqa: F401, E501
|
||||
|
||||
@ -70,7 +70,7 @@ internlm2_5-7b-chat-turbomind_fullbench:
|
||||
drop: 75
|
||||
hellaswag: 81.25
|
||||
TheoremQA: 6.25
|
||||
musr_average: 39.58
|
||||
musr_average: 37.5
|
||||
gsm8k: 68.75
|
||||
math: 75
|
||||
GPQA_diamond: 25
|
||||
|
||||
@ -1,2 +1,3 @@
|
||||
recursive-include opencompass/configs *.py *.yml *.json *.txt *.md
|
||||
recursive-include opencompass/openicl/icl_evaluator/hf_metrics *.py
|
||||
recursive-include opencompass/datasets *.py *.yml *.json *.txt *.md *.yaml
|
||||
|
||||
@ -15,13 +15,19 @@ datasets = [
|
||||
|
||||
models = [
|
||||
dict(
|
||||
path='Bailing-Lite-0830',
|
||||
path='Bailing-Lite-1116',
|
||||
token='xxxxxx', # set your key here or in environment variable BAILING_API_KEY
|
||||
url='https://bailingchat.alipay.com/chat/completions',
|
||||
type=BailingAPI,
|
||||
generation_kwargs={},
|
||||
query_per_second=1,
|
||||
max_seq_len=4096,
|
||||
max_out_len=11264,
|
||||
batch_size=1,
|
||||
generation_kwargs={
|
||||
'temperature': 0.01,
|
||||
'top_p': 1.0,
|
||||
'top_k': -1,
|
||||
'n': 1,
|
||||
'logprobs': 1,
|
||||
},
|
||||
),
|
||||
]
|
||||
|
||||
|
||||
28
configs/datasets/ruler/ruler_64k_gen.py
Normal file
28
configs/datasets/ruler/ruler_64k_gen.py
Normal file
@ -0,0 +1,28 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .ruler_cwe_gen import cwe_datasets as cwe # CWE
|
||||
from .ruler_fwe_gen import fwe_datasets as fwe # FWE
|
||||
from .ruler_niah_gen import niah_datasets as niah # Niah
|
||||
from .ruler_qa_gen import qa_datasets as qa # QA
|
||||
from .ruler_vt_gen import vt_datasets as vt # VT
|
||||
|
||||
|
||||
import_ds = sum((cwe, fwe, niah, qa, vt), [])
|
||||
|
||||
# Evaluation config
|
||||
NUM_SAMPLES = 100 # Change to the number of samples you need
|
||||
# Change the context lengths to be tested
|
||||
max_seq_lens = [1024 * 64]
|
||||
abbr_suffixs: list[str] = ['64k']
|
||||
|
||||
ruler_datasets = []
|
||||
|
||||
# Different seq length
|
||||
for max_seq_len, abbr_suffix in zip(max_seq_lens, abbr_suffixs):
|
||||
for dataset in import_ds:
|
||||
tmp_dataset = dataset.deepcopy()
|
||||
tmp_dataset['abbr'] = tmp_dataset['abbr'] + '_' + abbr_suffix
|
||||
tmp_dataset['num_samples'] = NUM_SAMPLES
|
||||
tmp_dataset['max_seq_length'] = max_seq_len
|
||||
ruler_datasets.append(tmp_dataset)
|
||||
@ -6,6 +6,7 @@ with read_base():
|
||||
from .ruler_8k_gen import ruler_datasets as ruler_8k_ds
|
||||
from .ruler_16k_gen import ruler_datasets as ruler_16k_ds
|
||||
from .ruler_32k_gen import ruler_datasets as ruler_32k_ds
|
||||
from .ruler_64k_gen import ruler_datasets as ruler_64k_ds
|
||||
from .ruler_128k_gen import ruler_datasets as ruler_128k_ds
|
||||
|
||||
ruler_combined_datasets = sum((v for k, v in locals().items() if k.endswith('_ds')), [])
|
||||
|
||||
@ -118,7 +118,7 @@ for _name, _prompt in sub_map.items():
|
||||
]),
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_seq_len=4096, max_out_len=2048),
|
||||
inferencer=dict(type=GenInferencer, max_seq_len=4096, max_out_len=4096),
|
||||
)
|
||||
|
||||
subjective_eval_cfg = dict(
|
||||
|
||||
@ -47,8 +47,3 @@ for _name in subjective_all_sets:
|
||||
infer_cfg=subjective_infer_cfg,
|
||||
eval_cfg=subjective_eval_cfg,
|
||||
))
|
||||
# ds1000_eval_cfg = dict(
|
||||
# evaluator=dict(type=DS1000Evaluator),
|
||||
# pred_role='BOT',
|
||||
# pred_postprocessor=dict(type=ds1000_postprocess),
|
||||
# )
|
||||
|
||||
32
configs/eval_PMMEval.py
Executable file
32
configs/eval_PMMEval.py
Executable file
@ -0,0 +1,32 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
from opencompass.models import HuggingFacewithChatTemplate
|
||||
|
||||
|
||||
with read_base():
|
||||
from opencompass.configs.models.qwen2_5.lmdeploy_qwen2_5_7b_instruct import models
|
||||
|
||||
# from opencompass.configs.datasets.PMMEval.flores_gen import PMMEval_flores_datasets
|
||||
# from opencompass.configs.datasets.PMMEval.humanevalxl_gen import PMMEval_HumanEvalXL_datasets
|
||||
# from opencompass.configs.datasets.PMMEval.mgsm_gen import PMMEval_MGSM_datasets
|
||||
# from opencompass.configs.datasets.PMMEval.mhellaswag_gen import PMMEval_MHellaswag_datasets
|
||||
# from opencompass.configs.datasets.PMMEval.mifeval_gen import PMMEval_MIFEval_datasets
|
||||
# from opencompass.configs.datasets.PMMEval.mlogiqa_gen import PMMEval_MLogiQA_datasets
|
||||
# from opencompass.configs.datasets.PMMEval.mmmlu_gen import PMMEval_MMMLU_datasets
|
||||
# from opencompass.configs.datasets.PMMEval.xnli import PMMEval_XNLI_datasets
|
||||
|
||||
from opencompass.configs.datasets.PMMEval.pmmeval_gen import PMMEval_datasets
|
||||
|
||||
from opencompass.configs.summarizers.PMMEval import summarizer
|
||||
|
||||
|
||||
# datasets = PMMEval_flores_datasets
|
||||
# datasets = PMMEval_HumanEvalXL_datasets
|
||||
# datasets = PMMEval_MGSM_datasets
|
||||
# datasets = PMMEval_MHellaswag_datasets
|
||||
# datasets = PMMEval_MIFEval_datasets
|
||||
# datasets = PMMEval_MLogiQA_datasets
|
||||
# datasets = PMMEval_MMMLU_datasets
|
||||
# datasets = PMMEval_XNLI_datasets
|
||||
|
||||
datasets = PMMEval_datasets
|
||||
9
configs/eval_korbench.py
Normal file
9
configs/eval_korbench.py
Normal file
@ -0,0 +1,9 @@
|
||||
from mmengine import read_base
|
||||
|
||||
with read_base():
|
||||
from opencompass.configs.datasets.korbench.korbench_single_0_shot_gen import korbench_0shot_single_datasets as zero_shot_datasets
|
||||
from opencompass.configs.datasets.korbench.korbench_single_3_shot_gen import korbench_3shot_single_datasets as three_shot_datasets
|
||||
from opencompass.configs.datasets.korbench.korbench_mixed_gen_d00bdd import korbench_mixed_datasets as mixed_datasets
|
||||
from opencompass.configs.models.hf_internlm.hf_internlm2_5_7b import models as hf_internlm2_5_7b
|
||||
datasets = zero_shot_datasets + three_shot_datasets + mixed_datasets
|
||||
models = hf_internlm2_5_7b
|
||||
47
configs/eval_math_llm_judge_internal.py
Normal file
47
configs/eval_math_llm_judge_internal.py
Normal file
@ -0,0 +1,47 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from opencompass.configs.datasets.math.math_0shot_llm_judge_v2_gen_31d777 import math_datasets
|
||||
|
||||
# 选择一个感兴趣的模型
|
||||
from opencompass.configs.models.qwen2_5.lmdeploy_qwen2_5_72b_instruct import models as qwen2_5_72b_instruct_model
|
||||
|
||||
eval_model_name = 'eval_model_name'
|
||||
postprocessor_model_name = 'postprocessor_model_name'
|
||||
eval_model_urls = ['http://0.0.0.0:23333/v1']
|
||||
postprocessor_model_urls = ['http://0.0.0.0:23333/v1']
|
||||
|
||||
datasets = sum([v for k, v in locals().items() if k.endswith('_datasets')], [])
|
||||
models = sum([v for k, v in locals().items() if k.endswith('_model')], [])
|
||||
|
||||
|
||||
for dataset in datasets:
|
||||
dataset['eval_cfg']['evaluator']['model_name'] = eval_model_name
|
||||
dataset['eval_cfg']['evaluator']['url'] = eval_model_urls
|
||||
dataset['eval_cfg']['evaluator']['post_url'] = postprocessor_model_urls
|
||||
dataset['eval_cfg']['evaluator']['post_model_name'] = postprocessor_model_name
|
||||
|
||||
|
||||
# -------------Inferen Stage ----------------------------------------
|
||||
|
||||
from opencompass.runners import LocalRunner
|
||||
from opencompass.partitioners import NaivePartitioner, NumWorkerPartitioner
|
||||
from opencompass.tasks import OpenICLInferTask, OpenICLEvalTask
|
||||
|
||||
infer = dict(
|
||||
partitioner=dict(type=NumWorkerPartitioner, num_worker=8),
|
||||
runner=dict(
|
||||
type=LocalRunner,
|
||||
max_num_workers=8,
|
||||
task=dict(type=OpenICLInferTask)
|
||||
),
|
||||
)
|
||||
|
||||
eval = dict(
|
||||
partitioner=dict(type=NaivePartitioner, n=10),
|
||||
runner=dict(
|
||||
type=LocalRunner,
|
||||
max_num_workers=256,
|
||||
task=dict(type=OpenICLEvalTask)
|
||||
),
|
||||
)
|
||||
45
configs/eval_simpleqa.py
Normal file
45
configs/eval_simpleqa.py
Normal file
@ -0,0 +1,45 @@
|
||||
# Most of the code in this file is copied from https://github.com/openai/simple-evals/blob/main/math_eval.py
|
||||
from mmengine.config import read_base
|
||||
from opencompass.partitioners import NaivePartitioner
|
||||
from opencompass.runners import LocalRunner
|
||||
from opencompass.tasks import OpenICLInferTask
|
||||
from opencompass.summarizers import DefaultSubjectiveSummarizer
|
||||
|
||||
|
||||
with read_base():
|
||||
from opencompass.configs.datasets.SimpleQA.simpleqa_gen import simpleqa_datasets
|
||||
from opencompass.configs.models.openai.gpt_4o_2024_05_13 import models as gpt_4o_2024_05_13_model
|
||||
|
||||
models = gpt_4o_2024_05_13_model # model for generation
|
||||
judge_models = gpt_4o_2024_05_13_model # model for evaluation
|
||||
|
||||
datasets = sum([v for k, v in locals().items() if k.endswith('_datasets')], [])
|
||||
summarizer = dict(type=DefaultSubjectiveSummarizer)
|
||||
|
||||
# -------------Inferen Stage ----------------------------------------
|
||||
|
||||
from opencompass.runners import LocalRunner
|
||||
from opencompass.partitioners import NaivePartitioner, NumWorkerPartitioner
|
||||
from opencompass.tasks import OpenICLInferTask, OpenICLEvalTask
|
||||
from opencompass.tasks.subjective_eval import SubjectiveEvalTask
|
||||
from opencompass.partitioners.sub_naive import SubjectiveNaivePartitioner
|
||||
|
||||
infer = dict(
|
||||
partitioner=dict(type=NumWorkerPartitioner, num_worker=8),
|
||||
runner=dict(
|
||||
type=LocalRunner,
|
||||
max_num_workers=8,
|
||||
task=dict(type=OpenICLInferTask)
|
||||
),
|
||||
)
|
||||
|
||||
eval = dict(
|
||||
partitioner=dict(
|
||||
type=SubjectiveNaivePartitioner,
|
||||
models=[gpt_4o_2024_05_13_model],
|
||||
judge_models=[gpt_4o_2024_05_13_model],
|
||||
),
|
||||
runner=dict(type=LocalRunner,
|
||||
max_num_workers=256,
|
||||
task=dict(type=SubjectiveEvalTask)),
|
||||
)
|
||||
@ -10,21 +10,19 @@ api_meta_template = dict(
|
||||
|
||||
models = [
|
||||
dict(
|
||||
path='Bailing-Pro-0920',
|
||||
path='Bailing-Lite-1116',
|
||||
token='', # set your key here or in environment variable BAILING_API_KEY
|
||||
url='https://bailingchat.alipay.com/chat/completions',
|
||||
type=BailingAPI,
|
||||
meta_template=api_meta_template,
|
||||
query_per_second=1,
|
||||
max_seq_len=4096,
|
||||
max_out_len=11264,
|
||||
batch_size=1,
|
||||
generation_kwargs={
|
||||
'temperature': 0.4,
|
||||
'temperature': 0.01,
|
||||
'top_p': 1.0,
|
||||
'top_k': -1,
|
||||
'n': 1,
|
||||
'logprobs': 1,
|
||||
'use_beam_search': False,
|
||||
},
|
||||
),
|
||||
]
|
||||
@ -10,21 +10,19 @@ api_meta_template = dict(
|
||||
|
||||
models = [
|
||||
dict(
|
||||
path='Bailing-Pro-0920',
|
||||
path='Bailing-Pro-1120',
|
||||
token='', # set your key here or in environment variable BAILING_API_KEY
|
||||
url='https://bailingchat.alipay.com/chat/completions',
|
||||
type=BailingAPI,
|
||||
meta_template=api_meta_template,
|
||||
query_per_second=1,
|
||||
max_seq_len=4096,
|
||||
max_out_len=11264,
|
||||
batch_size=1,
|
||||
generation_kwargs={
|
||||
'temperature': 0.4,
|
||||
'temperature': 0.01,
|
||||
'top_p': 1.0,
|
||||
'top_k': -1,
|
||||
'n': 1,
|
||||
'logprobs': 1,
|
||||
'use_beam_search': False,
|
||||
},
|
||||
),
|
||||
]
|
||||
@ -13,7 +13,7 @@ default_ruler_tasks = [
|
||||
'ruler_qa_squad',
|
||||
'ruler_qa_hotpotqa',
|
||||
]
|
||||
context_window_sizes = ['4k', '8k', '16k', '32k', '128k', '1m']
|
||||
context_window_sizes = ['4k', '8k', '16k', '32k', '64k', '128k', '1m']
|
||||
|
||||
ruler_summary_groups = []
|
||||
for context_window_size in context_window_sizes:
|
||||
|
||||
@ -35,7 +35,12 @@ ruler_32k_summarizer = dict(
|
||||
[v for k, v in locals().items() if k.endswith('_summary_groups')], []
|
||||
),
|
||||
)
|
||||
|
||||
ruler_64k_summarizer = dict(
|
||||
dataset_abbrs=['ruler_64k'],
|
||||
summary_groups=sum(
|
||||
[v for k, v in locals().items() if k.endswith('_summary_groups')], []
|
||||
),
|
||||
)
|
||||
ruler_128k_summarizer = dict(
|
||||
dataset_abbrs=['ruler_128k'],
|
||||
summary_groups=sum(
|
||||
@ -56,6 +61,7 @@ ruler_combined_summarizer = dict(
|
||||
'ruler_8k',
|
||||
'ruler_16k',
|
||||
'ruler_32k',
|
||||
'ruler_64k',
|
||||
'ruler_128k',
|
||||
'ruler_1m',
|
||||
],
|
||||
|
||||
@ -1,8 +1,9 @@
|
||||
__version__ = '0.3.6'
|
||||
__version__ = '0.3.7'
|
||||
|
||||
|
||||
def _warn_about_config_migration():
|
||||
import warnings
|
||||
|
||||
warnings.warn(
|
||||
'Starting from v0.4.0, all AMOTIC configuration files currently '
|
||||
'located in `./configs/datasets`, `./configs/models`, and '
|
||||
@ -10,7 +11,8 @@ def _warn_about_config_migration():
|
||||
'`opencompass/configs/` package. Please update your configuration '
|
||||
'file paths accordingly.',
|
||||
UserWarning, # Changed to UserWarning
|
||||
stacklevel=2)
|
||||
stacklevel=2,
|
||||
)
|
||||
|
||||
|
||||
# Trigger the warning
|
||||
|
||||
@ -0,0 +1,47 @@
|
||||
# ARC Prize Public Evaluation
|
||||
|
||||
#### Overview
|
||||
The spirit of ARC Prize is to open source progress towards AGI. To win prize money, you will be required to publish reproducible code/methods into public domain.
|
||||
|
||||
ARC Prize measures AGI progress using the [ARC-AGI private evaluation set](https://arcprize.org/guide#private), [the leaderboard is here](https://arcprize.org/leaderboard), and the Grand Prize is unlocked once the first team reaches [at least 85%](https://arcprize.org/guide#grand-prize-goal).
|
||||
|
||||
Note: the private evaluation set imposes limitations on solutions (eg. no internet access, so no GPT-4/Claude/etc). There is a [secondary leaderboard](https://arcprize.org/leaderboard) called ARC-AGI-Pub, it measures the [public evaluation set](https://arcprize.org/guide#public-tasks) and imposes no limits but it is not part of ARC Prize 2024 at this time.
|
||||
|
||||
|
||||
#### Tasks
|
||||
ARC-AGI tasks are a series of three to five input and output tasks followed by a final task with only the input listed. Each task tests the utilization of a specific learned skill based on a minimal number of cognitive priors.
|
||||
|
||||
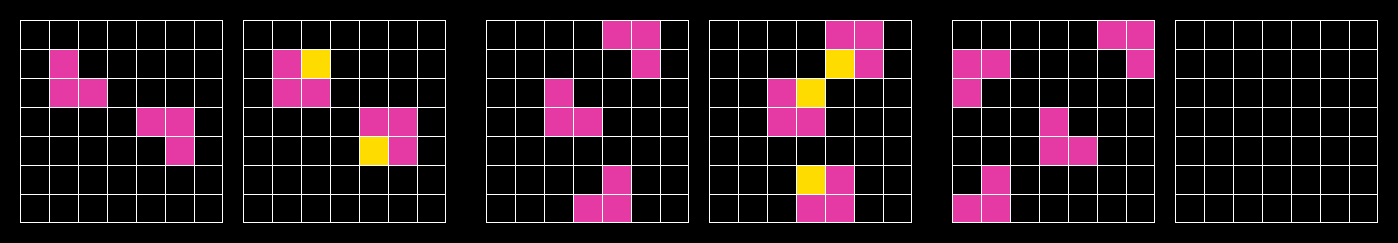
|
||||
|
||||
Tasks are represented as JSON lists of integers. These JSON objects can also be represented visually as a grid of colors using an ARC-AGI task viewer.
|
||||
|
||||
A successful submission is a pixel-perfect description (color and position) of the final task's output.
|
||||
|
||||
#### Format
|
||||
|
||||
As mentioned above, tasks are stored in JSON format. Each JSON file consists of two key-value pairs.
|
||||
|
||||
`train`: a list of two to ten input/output pairs (typically three.) These are used for your algorithm to infer a rule.
|
||||
|
||||
`test`: a list of one to three input/output pairs (typically one.) Your model should apply the inferred rule from the train set and construct an output solution. You will have access to the output test solution on the public data. The output solution on the private evaluation set will not be revealed.
|
||||
|
||||
Here is an example of a simple ARC-AGI task that has three training pairs along with a single test pair. Each pair is shown as a 2x2 grid. There are four colors represented by the integers 1, 4, 6, and 8. Which actual color (red/green/blue/black) is applied to each integer is arbitrary and up to you.
|
||||
|
||||
```json
|
||||
{
|
||||
"train": [
|
||||
{"input": [[1, 0], [0, 0]], "output": [[1, 1], [1, 1]]},
|
||||
{"input": [[0, 0], [4, 0]], "output": [[4, 4], [4, 4]]},
|
||||
{"input": [[0, 0], [6, 0]], "output": [[6, 6], [6, 6]]}
|
||||
],
|
||||
"test": [
|
||||
{"input": [[0, 0], [0, 8]], "output": [[8, 8], [8, 8]]}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
#### Performance
|
||||
|
||||
| Qwen2.5-72B-Instruct | LLaMA3.1-70B-Instruct | gemma-2-27b-it |
|
||||
| ----- | ----- | ----- |
|
||||
| 0.09 | 0.06 | 0.05 |
|
||||
@ -0,0 +1,4 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .arc_prize_public_evaluation_gen_872059 import arc_prize_public_evaluation_datasets # noqa: F401, F403
|
||||
@ -0,0 +1,56 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets.arc_prize_public_evaluation import ARCPrizeDataset, ARCPrizeEvaluator
|
||||
|
||||
|
||||
# The system_prompt defines the initial instructions for the model,
|
||||
# setting the context for solving ARC tasks.
|
||||
system_prompt = '''You are a puzzle solving wizard. You are given a puzzle from the abstraction and reasoning corpus developed by Francois Chollet.'''
|
||||
|
||||
# User message template is a template for creating user prompts. It includes placeholders for training data and test input data,
|
||||
# guiding the model to learn the rule and apply it to solve the given puzzle.
|
||||
user_message_template = '''Here are the example input and output pairs from which you should learn the underlying rule to later predict the output for the given test input:
|
||||
----------------------------------------
|
||||
{training_data}
|
||||
----------------------------------------
|
||||
Now, solve the following puzzle based on its input grid by applying the rules you have learned from the training data.:
|
||||
----------------------------------------
|
||||
[{{'input': {input_test_data}, 'output': [[]]}}]
|
||||
----------------------------------------
|
||||
What is the output grid? Only provide the output grid in the form as in the example input and output pairs. Do not provide any additional information:'''
|
||||
|
||||
|
||||
arc_prize_public_evaluation_reader_cfg = dict(
|
||||
input_columns=['training_data', 'input_test_data'],
|
||||
output_column='output_test_data'
|
||||
)
|
||||
|
||||
arc_prize_public_evaluation_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(role='SYSTEM', prompt=system_prompt),
|
||||
dict(role='HUMAN', prompt=user_message_template),
|
||||
],
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=2048)
|
||||
)
|
||||
|
||||
arc_prize_public_evaluation_eval_cfg = dict(
|
||||
evaluator=dict(type=ARCPrizeEvaluator)
|
||||
)
|
||||
|
||||
arc_prize_public_evaluation_datasets = [
|
||||
dict(
|
||||
abbr='ARC_Prize_Public_Evaluation',
|
||||
type=ARCPrizeDataset,
|
||||
path='opencompass/arc_prize_public_evaluation',
|
||||
reader_cfg=arc_prize_public_evaluation_reader_cfg,
|
||||
infer_cfg=arc_prize_public_evaluation_infer_cfg,
|
||||
eval_cfg=arc_prize_public_evaluation_eval_cfg
|
||||
)
|
||||
]
|
||||
4
opencompass/configs/datasets/PMMEval/flores_gen.py
Executable file
4
opencompass/configs/datasets/PMMEval/flores_gen.py
Executable file
@ -0,0 +1,4 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .flores_gen_2697d7 import PMMEval_flores_datasets
|
||||
65
opencompass/configs/datasets/PMMEval/flores_gen_2697d7.py
Executable file
65
opencompass/configs/datasets/PMMEval/flores_gen_2697d7.py
Executable file
@ -0,0 +1,65 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets.PMMEval import PMMEvalFloresDataset, PMMEvalFloresEvaluator, pmmeval_flores_postprocess
|
||||
|
||||
NATURAL_LANGUAGE_FULLNAMES_FLORES = ['Chinese', 'Arabic', 'Spanish', 'French', 'Japanese', 'Korean', 'Portuguese', 'Thai', 'Vietnamese']
|
||||
|
||||
PROMPT = {
|
||||
"Chinese": "将这个句子从英语翻译成中文。\n\n{src}",
|
||||
"Arabic": "ترجم هذه الجملة من الإنجليزية إلى العربية.\n\n{src}",
|
||||
"Spanish": "Traduce esta oración del inglés al español.\n\n{src}",
|
||||
"Japanese": "この文を英語から日本語に翻訳してください。\n\n{src}",
|
||||
"Korean": "이 문장을 영어에서 한국어로 번역하세요.\n\n{src}",
|
||||
"Thai": "แปลประโยคนี้จากภาษาอังกฤษเป็นภาษาไทย.\n\n{src}",
|
||||
"French": "Traduisez cette phrase de l'anglais en français.\n\n{src}",
|
||||
"Portuguese": "Traduza esta frase do inglês para o português.\n\n{src}",
|
||||
"Vietnamese": "Dịch câu này từ tiếng Anh sang tiếng Việt.\n\n{src}"
|
||||
}
|
||||
|
||||
PMMEval_flores_datasets = list()
|
||||
|
||||
# Add flores_200
|
||||
|
||||
PMMEval_flores_reader_cfg = dict(
|
||||
input_columns=['src'],
|
||||
output_column='tgt',
|
||||
test_split='test'
|
||||
)
|
||||
|
||||
|
||||
PMMEval_flores_datasets = list()
|
||||
|
||||
for lang_fullname in NATURAL_LANGUAGE_FULLNAMES_FLORES:
|
||||
PMMEval_flores_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt=PROMPT[lang_fullname]
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer),
|
||||
)
|
||||
|
||||
PMMEval_flores_eval_cfg = dict(
|
||||
evaluator=dict(type=PMMEvalFloresEvaluator),
|
||||
pred_role='BOT',
|
||||
pred_postprocessor=dict(type=pmmeval_flores_postprocess, lang_fullname=lang_fullname)
|
||||
)
|
||||
|
||||
PMMEval_flores_datasets.append(
|
||||
dict(
|
||||
abbr=f'flores-{lang_fullname}',
|
||||
type=PMMEvalFloresDataset,
|
||||
path='P-MMEval',
|
||||
lang_fullname=lang_fullname,
|
||||
reader_cfg=PMMEval_flores_reader_cfg,
|
||||
infer_cfg=PMMEval_flores_infer_cfg,
|
||||
eval_cfg=PMMEval_flores_eval_cfg)
|
||||
)
|
||||
4
opencompass/configs/datasets/PMMEval/humanevalxl_gen.py
Executable file
4
opencompass/configs/datasets/PMMEval/humanevalxl_gen.py
Executable file
@ -0,0 +1,4 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .humanevalxl_gen_4dfef4 import PMMEval_HumanEvalXL_datasets
|
||||
49
opencompass/configs/datasets/PMMEval/humanevalxl_gen_bdec92.py
Executable file
49
opencompass/configs/datasets/PMMEval/humanevalxl_gen_bdec92.py
Executable file
@ -0,0 +1,49 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets.PMMEval import PMMEvalHumanEvalXLDataset, PMMEvalHumanEvalXLEvaluator
|
||||
|
||||
NATURAL_LANGUAGE_FULLNAMES = ['English', 'Chinese', 'Arabic', 'Spanish', 'French', 'Japanese', 'Korean', 'Portuguese', 'Thai', 'Vietnamese']
|
||||
|
||||
PMMEval_HumanEvalXL_datasets = list()
|
||||
|
||||
PMMEval_HumanEvalXL_reader_cfg = dict(
|
||||
input_columns=['task_id', 'prompt', 'entry_point', 'test', 'language', 'description', 'natural_language'],
|
||||
output_column='declaration',
|
||||
test_split='test'
|
||||
)
|
||||
|
||||
PMMEval_HumanEvalXL_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template='{prompt}'),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer),
|
||||
)
|
||||
|
||||
|
||||
PMMEval_HumanEvalXL_datasets = list()
|
||||
|
||||
for lang_fullname in NATURAL_LANGUAGE_FULLNAMES:
|
||||
for program_lang in ['python', 'java', 'javascript']:
|
||||
|
||||
PMMEval_HumanEvalXL_eval_cfg = dict(
|
||||
evaluator=dict(
|
||||
type=PMMEvalHumanEvalXLEvaluator,
|
||||
language=program_lang,
|
||||
text_language=lang_fullname,
|
||||
ip_address='localhost',
|
||||
port=5001),
|
||||
pred_role='BOT')
|
||||
|
||||
PMMEval_HumanEvalXL_datasets.append(
|
||||
dict(
|
||||
abbr=f'humanevalxl-{program_lang}-{lang_fullname}',
|
||||
type=PMMEvalHumanEvalXLDataset,
|
||||
path='P-MMEval',
|
||||
lang=lang_fullname,
|
||||
program_lang=program_lang,
|
||||
reader_cfg=PMMEval_HumanEvalXL_reader_cfg,
|
||||
infer_cfg=PMMEval_HumanEvalXL_infer_cfg,
|
||||
eval_cfg=PMMEval_HumanEvalXL_eval_cfg)
|
||||
)
|
||||
4
opencompass/configs/datasets/PMMEval/mgsm_gen.py
Executable file
4
opencompass/configs/datasets/PMMEval/mgsm_gen.py
Executable file
@ -0,0 +1,4 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .mgsm_gen_679720 import PMMEval_MGSM_datasets
|
||||
62
opencompass/configs/datasets/PMMEval/mgsm_gen_679720.py
Executable file
62
opencompass/configs/datasets/PMMEval/mgsm_gen_679720.py
Executable file
@ -0,0 +1,62 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets.PMMEval import PMMEvalMGSMDataset, PMMEvalMGSMEvaluator
|
||||
|
||||
NATURAL_LANGUAGE_CODES = ['en', 'zh', 'ar', 'es', 'fr', 'ja', 'ko', 'pt', 'th', 'vi']
|
||||
|
||||
LANG_TO_INSTRUCTIONS = {
|
||||
"en": "Solve this math problem. Give the reasoning steps before giving the final answer on the last line by itself in the format of \"The answer is \". Do not add anything other than the integer answer after \"The answer is \".\n\n{question}",
|
||||
"es": "Solve this math problem. Give the reasoning steps before giving the final answer on the last line by itself in the format of \"La respuesta es \". Do not add anything other than the integer answer after \"La respuesta es \".\n\n{question}",
|
||||
"fr": "Solve this math problem. Give the reasoning steps before giving the final answer on the last line by itself in the format of \"La réponse est \". Do not add anything other than the integer answer after \"La réponse est \".\n\n{question}",
|
||||
"zh": "Solve this math problem. Give the reasoning steps before giving the final answer on the last line by itself in the format of \"答案是 \". Do not add anything other than the integer answer after \"答案是 \".\n\n{question}",
|
||||
"ja": "Solve this math problem. Give the reasoning steps before giving the final answer on the last line by itself in the format of \"答えは \". Do not add anything other than the integer answer after \"答えは \".\n\n{question}",
|
||||
"th": "Solve this math problem. Give the reasoning steps before giving the final answer on the last line by itself in the format of \"คำตอบคือ \". Do not add anything other than the integer answer after \"คำตอบคือ \".\n\n{question}",
|
||||
"ko": "Solve this math problem. Give the reasoning steps before giving the final answer on the last line by itself in the format of \"답변은 \". Do not add anything other than the integer answer after \"답변은 \".\n\n{question}",
|
||||
"pt": "Solve this math problem. Give the reasoning steps before giving the final answer on the last line by itself in the format of \"A resposta é \". Do not add anything other than the integer answer after \"A resposta é \".\n\n{question}",
|
||||
"vi": "Solve this math problem. Give the reasoning steps before giving the final answer on the last line by itself in the format of \"Câu trả lời là \". Do not add anything other than the integer answer after \"Câu trả lời là \".\n\n{question}",
|
||||
"ar": "Solve this math problem. Give the reasoning steps before giving the final answer on the last line by itself in the format of \"الجواب هو \". Do not add anything other than the integer answer after \"الجواب هو \".\n\n{question}"
|
||||
}
|
||||
|
||||
PMMEval_MGSM_datasets = list()
|
||||
|
||||
# Add flores_200
|
||||
|
||||
PMMEval_MGSM_reader_cfg = dict(
|
||||
input_columns=['question'],
|
||||
output_column='answer',
|
||||
test_split='test'
|
||||
)
|
||||
|
||||
PMMEval_MGSM_eval_cfg = dict(
|
||||
evaluator=dict(type=PMMEvalMGSMEvaluator),
|
||||
pred_role='BOT')
|
||||
|
||||
|
||||
for lang_code in NATURAL_LANGUAGE_CODES:
|
||||
PMMEval_MGSM_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt=LANG_TO_INSTRUCTIONS[lang_code]
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer),
|
||||
)
|
||||
|
||||
PMMEval_MGSM_datasets.append(
|
||||
dict(
|
||||
abbr=f'mgsm-{lang_code}',
|
||||
type=PMMEvalMGSMDataset,
|
||||
path='P-MMEval',
|
||||
lang=lang_code,
|
||||
reader_cfg=PMMEval_MGSM_reader_cfg,
|
||||
infer_cfg=PMMEval_MGSM_infer_cfg,
|
||||
eval_cfg=PMMEval_MGSM_eval_cfg)
|
||||
)
|
||||
4
opencompass/configs/datasets/PMMEval/mhellaswag_gen.py
Executable file
4
opencompass/configs/datasets/PMMEval/mhellaswag_gen.py
Executable file
@ -0,0 +1,4 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .mhellaswag_gen_1a6b73 import PMMEval_MHellaswag_datasets
|
||||
54
opencompass/configs/datasets/PMMEval/mhellaswag_gen_1a6b73.py
Executable file
54
opencompass/configs/datasets/PMMEval/mhellaswag_gen_1a6b73.py
Executable file
@ -0,0 +1,54 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets.PMMEval import PMMEvalMHellaswagDataset, PMMEvalMHellaswagEvaluator, pmmeval_mhellaswag_postprocess
|
||||
|
||||
NATURAL_LANGUAGE_CODES = ['en', 'zh', 'ar', 'es', 'fr', 'ja', 'ko', 'pt', 'th', 'vi']
|
||||
|
||||
PMMEVAL_MHELLASWAG_TEMPLATE = "Input: {ctx}\nOptions: \nA. {option_1}\nB. {option_2}\nC. {option_3}\nD. {option_4}\nPick the correct ending for the sentence from A, B, C, and D, and return it in the following JSON format:\n{\"answer\": \"[choice]\"}\nwhere [choice] must be one of A, B, C or D."
|
||||
|
||||
PMMEval_MHellaswag_datasets = list()
|
||||
|
||||
PMMEval_MHellaswag_reader_cfg = dict(
|
||||
input_columns=['ctx', 'option_1', 'option_2', 'option_3', 'option_4'],
|
||||
output_column='label',
|
||||
test_split='test'
|
||||
)
|
||||
|
||||
PMMEval_MHellaswag_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt=PMMEVAL_MHELLASWAG_TEMPLATE
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer),
|
||||
)
|
||||
|
||||
|
||||
PMMEval_MHellaswag_datasets = list()
|
||||
|
||||
|
||||
for lang_code in NATURAL_LANGUAGE_CODES:
|
||||
PMMEval_MHellaswag_eval_cfg = dict(
|
||||
evaluator=dict(type=PMMEvalMHellaswagEvaluator),
|
||||
pred_role='BOT',
|
||||
pred_postprocessor=dict(type=pmmeval_mhellaswag_postprocess, lang_code=lang_code)
|
||||
)
|
||||
|
||||
PMMEval_MHellaswag_datasets.append(
|
||||
dict(
|
||||
abbr=f'mhellaswag-{lang_code}',
|
||||
type=PMMEvalMHellaswagDataset,
|
||||
path='P-MMEval',
|
||||
lang=lang_code,
|
||||
reader_cfg=PMMEval_MHellaswag_reader_cfg,
|
||||
infer_cfg=PMMEval_MHellaswag_infer_cfg,
|
||||
eval_cfg=PMMEval_MHellaswag_eval_cfg)
|
||||
)
|
||||
4
opencompass/configs/datasets/PMMEval/mifeval_gen.py
Executable file
4
opencompass/configs/datasets/PMMEval/mifeval_gen.py
Executable file
@ -0,0 +1,4 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .mifeval_gen_79f8fb import PMMEval_MIFEval_datasets
|
||||
51
opencompass/configs/datasets/PMMEval/mifeval_gen_79f8fb.py
Executable file
51
opencompass/configs/datasets/PMMEval/mifeval_gen_79f8fb.py
Executable file
@ -0,0 +1,51 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets.PMMEval import PMMEvalMIFEvalDataset, PMMEvalMIFEvalEvaluator, pmmeval_mifeval_postprocess
|
||||
|
||||
NATURAL_LANGUAGE_CODES = ['en', 'zh', 'ar', 'es', 'fr', 'ja', 'ko', 'pt', 'th', 'vi']
|
||||
|
||||
PMMEVAL_MIFEVAL_TEMPLATE = "{prompt}"
|
||||
|
||||
PMMEval_MIFEval_datasets = list()
|
||||
|
||||
PMMEval_MIFEval_reader_cfg = dict(
|
||||
input_columns=['prompt', 'instruction_id_list', 'kwargs'],
|
||||
output_column=None,
|
||||
test_split='test'
|
||||
)
|
||||
|
||||
|
||||
PMMEval_MIFEval_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt=PMMEVAL_MIFEVAL_TEMPLATE
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer),
|
||||
)
|
||||
|
||||
for lang_code in NATURAL_LANGUAGE_CODES:
|
||||
PMMEval_MIFEval_eval_cfg = dict(
|
||||
evaluator=dict(type=PMMEvalMIFEvalEvaluator),
|
||||
pred_role='BOT',
|
||||
pred_postprocessor=dict(type=pmmeval_mifeval_postprocess, lang_code=lang_code)
|
||||
)
|
||||
|
||||
PMMEval_MIFEval_datasets.append(
|
||||
dict(
|
||||
abbr=f'mifeval-{lang_code}',
|
||||
type=PMMEvalMIFEvalDataset,
|
||||
path='P-MMEval',
|
||||
lang=lang_code,
|
||||
reader_cfg=PMMEval_MIFEval_reader_cfg,
|
||||
infer_cfg=PMMEval_MIFEval_infer_cfg,
|
||||
eval_cfg=PMMEval_MIFEval_eval_cfg)
|
||||
)
|
||||
4
opencompass/configs/datasets/PMMEval/mlogiqa_gen.py
Executable file
4
opencompass/configs/datasets/PMMEval/mlogiqa_gen.py
Executable file
@ -0,0 +1,4 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .mlogiqa_gen_36c4f9 import PMMEval_MLogiQA_datasets
|
||||
50
opencompass/configs/datasets/PMMEval/mlogiqa_gen_36c4f9.py
Executable file
50
opencompass/configs/datasets/PMMEval/mlogiqa_gen_36c4f9.py
Executable file
@ -0,0 +1,50 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets.PMMEval import PMMEvalMLogiQADataset, PMMEvalMLogiQAEvaluator, pmmeval_mlogiqa_postprocess
|
||||
|
||||
NATURAL_LANGUAGE_CODES = ['en', 'zh', 'ar', 'es', 'fr', 'ja', 'ko', 'pt', 'th', 'vi']
|
||||
|
||||
PMMEVAL_MLOGIQA_TEMPLATE = "Passage: {context}\nQuestion: {question}\nChoices:\nA.{option_1}\nB.{option_2}\nC.{option_3}\nD.{option_4}\nPlease choose the most suitable one among A, B, C and D as the answer to this question, and return it in the following JSON format:\n{'answer': '[choice]'}\nwhere [choice] must be one of A, B, C and D."
|
||||
|
||||
PMMEval_MLogiQA_datasets = []
|
||||
|
||||
|
||||
PMMEval_MLogiQA_reader_cfg = dict(
|
||||
input_columns=['context', 'question', 'option_1', 'option_2', 'option_3', 'option_4'],
|
||||
output_column='answer',
|
||||
train_split='test')
|
||||
|
||||
PMMEval_MLogiQA_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt=PMMEVAL_MLOGIQA_TEMPLATE
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer),
|
||||
)
|
||||
|
||||
|
||||
for lang_code in NATURAL_LANGUAGE_CODES:
|
||||
PMMEval_MLogiQA_eval_cfg = dict(
|
||||
evaluator=dict(type=PMMEvalMLogiQAEvaluator),
|
||||
pred_role='BOT',
|
||||
pred_postprocessor=dict(type=pmmeval_mlogiqa_postprocess, lang_code=lang_code))
|
||||
|
||||
PMMEval_MLogiQA_datasets.append(
|
||||
dict(
|
||||
abbr=f'mlogiqa-{lang_code}',
|
||||
type=PMMEvalMLogiQADataset,
|
||||
path='P-MMEval',
|
||||
lang=lang_code,
|
||||
reader_cfg=PMMEval_MLogiQA_reader_cfg,
|
||||
infer_cfg=PMMEval_MLogiQA_infer_cfg,
|
||||
eval_cfg=PMMEval_MLogiQA_eval_cfg)
|
||||
)
|
||||
4
opencompass/configs/datasets/PMMEval/mmmlu_gen.py
Executable file
4
opencompass/configs/datasets/PMMEval/mmmlu_gen.py
Executable file
@ -0,0 +1,4 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .mmmlu_gen_d5017d import PMMEval_MMMLU_datasets
|
||||
52
opencompass/configs/datasets/PMMEval/mmmlu_gen_d5017d.py
Executable file
52
opencompass/configs/datasets/PMMEval/mmmlu_gen_d5017d.py
Executable file
@ -0,0 +1,52 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets.PMMEval import PMMEvalMMMLUDataset, PMMEvalMMMLUEvaluator, pmmeval_mmmlu_postprocess
|
||||
|
||||
NATURAL_LANGUAGE_CODES_MMMLU = ['EN-US', 'ZH-CN', 'AR-XY', 'ES-LA', 'FR-FR', 'JA-JP', 'KO-KR', 'PT-BR', 'TH-TL', 'VI-VT']
|
||||
|
||||
PMMEVAL_MMMLU_TEMPLATE = "The following is a multiple-choice question. Please choose the most suitable one among A, B, C and D as the answer to this question, and return it in the following JSON format:\n{\"answer\": \"[choice]\"}\nwhere [choice] must be one of A, B, C and D.\n\n{Question}\nA. {A}\nB. {B}\nC. {C}\nD. {D}"
|
||||
|
||||
PMMEval_MMMLU_datasets = []
|
||||
|
||||
|
||||
PMMEval_MMMLU_reader_cfg = dict(
|
||||
input_columns=['Question', 'A', 'B', 'C', 'D'],
|
||||
output_column='Answer',
|
||||
train_split='test')
|
||||
|
||||
|
||||
PMMEval_MMMLU_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt=PMMEVAL_MMMLU_TEMPLATE
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer),
|
||||
)
|
||||
|
||||
|
||||
for lang_code in NATURAL_LANGUAGE_CODES_MMMLU:
|
||||
PMMEval_MMMLU_eval_cfg = dict(
|
||||
evaluator=dict(type=PMMEvalMMMLUEvaluator),
|
||||
pred_role='BOT',
|
||||
pred_postprocessor=dict(type=pmmeval_mmmlu_postprocess, lang_code=lang_code))
|
||||
|
||||
PMMEval_MMMLU_datasets.append(
|
||||
dict(
|
||||
abbr=f'mmmlu-{lang_code}',
|
||||
type=PMMEvalMMMLUDataset,
|
||||
path='P-MMEval',
|
||||
lang=lang_code,
|
||||
difficulty='all',
|
||||
reader_cfg=PMMEval_MMMLU_reader_cfg,
|
||||
infer_cfg=PMMEval_MMMLU_infer_cfg,
|
||||
eval_cfg=PMMEval_MMMLU_eval_cfg)
|
||||
)
|
||||
14
opencompass/configs/datasets/PMMEval/pmmeval_gen.py
Executable file
14
opencompass/configs/datasets/PMMEval/pmmeval_gen.py
Executable file
@ -0,0 +1,14 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .flores_gen_2697d7 import PMMEval_flores_datasets
|
||||
from .humanevalxl_gen_bdec92 import PMMEval_HumanEvalXL_datasets
|
||||
from .mgsm_gen_679720 import PMMEval_MGSM_datasets
|
||||
from .mhellaswag_gen_1a6b73 import PMMEval_MHellaswag_datasets
|
||||
from .mifeval_gen_79f8fb import PMMEval_MIFEval_datasets
|
||||
from .mlogiqa_gen_36c4f9 import PMMEval_MLogiQA_datasets
|
||||
from .mmmlu_gen_d5017d import PMMEval_MMMLU_datasets
|
||||
from .xnli_gen_973734 import PMMEval_XNLI_datasets
|
||||
|
||||
|
||||
PMMEval_datasets = sum((v for k, v in locals().items() if k.endswith('_datasets')), [])
|
||||
4
opencompass/configs/datasets/PMMEval/xnli_gen.py
Executable file
4
opencompass/configs/datasets/PMMEval/xnli_gen.py
Executable file
@ -0,0 +1,4 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .xnli_gen_973734 import PMMEval_XNLI_datasets
|
||||
60
opencompass/configs/datasets/PMMEval/xnli_gen_973734.py
Executable file
60
opencompass/configs/datasets/PMMEval/xnli_gen_973734.py
Executable file
@ -0,0 +1,60 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets.PMMEval import PMMEvalXNLIDataset, PMMEvalXNLIEvaluator, pmmeval_xnli_postprocess
|
||||
|
||||
NATURAL_LANGUAGE_CODES = ['en', 'zh', 'ar', 'es', 'fr', 'ja', 'ko', 'pt', 'th', 'vi']
|
||||
|
||||
PMMEVAL_XNLI_TEMPLATE = """Take the following as truth: {premise}
|
||||
Then the following statement: \"{statement}\" is
|
||||
Options:
|
||||
A. true
|
||||
B. inconclusive
|
||||
C. false
|
||||
Select the correct option from A, B, and C, and return it in the following JSON format:
|
||||
{"answer": "[choice]"}
|
||||
where [choice] must be one of A, B, and C."""
|
||||
|
||||
PMMEval_XNLI_datasets = list()
|
||||
|
||||
# Add flores_200
|
||||
|
||||
PMMEval_XNLI_reader_cfg = dict(
|
||||
input_columns=['premise', 'statement'],
|
||||
output_column='answer',
|
||||
test_split='test'
|
||||
)
|
||||
|
||||
|
||||
PMMEval_XNLI_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt=PMMEVAL_XNLI_TEMPLATE
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer),
|
||||
)
|
||||
|
||||
for lang_code in NATURAL_LANGUAGE_CODES:
|
||||
PMMEval_XNLI_eval_cfg = dict(
|
||||
evaluator=dict(type=PMMEvalXNLIEvaluator),
|
||||
pred_role='BOT',
|
||||
pred_postprocessor=dict(type=pmmeval_xnli_postprocess, lang_code=lang_code))
|
||||
|
||||
PMMEval_XNLI_datasets.append(
|
||||
dict(
|
||||
abbr=f'xnli-{lang_code}',
|
||||
type=PMMEvalXNLIDataset,
|
||||
path='P-MMEval',
|
||||
lang=lang_code,
|
||||
reader_cfg=PMMEval_XNLI_reader_cfg,
|
||||
infer_cfg=PMMEval_XNLI_infer_cfg,
|
||||
eval_cfg=PMMEval_XNLI_eval_cfg)
|
||||
)
|
||||
10
opencompass/configs/datasets/SimpleQA/README.md
Normal file
10
opencompass/configs/datasets/SimpleQA/README.md
Normal file
@ -0,0 +1,10 @@
|
||||
# OpenCompass SimpleQA dataset config for evaluation
|
||||
|
||||
## 1. Introduction
|
||||
|
||||
SimpleQA is a benchmark that evaluates the ability of language models to answer short, fact-seeking questions by OpenAI.
|
||||
The original site is https://github.com/openai/simple-evals.
|
||||
|
||||
## 2. How to use
|
||||
|
||||
Please refer to the demo evaluation script `/opencompass/configs/mine/simpleqa_eval.py`.
|
||||
4
opencompass/configs/datasets/SimpleQA/simpleqa_gen.py
Normal file
4
opencompass/configs/datasets/SimpleQA/simpleqa_gen.py
Normal file
@ -0,0 +1,4 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .simpleqa_gen_0283c3 import simpleqa_datasets # noqa: F401, F403
|
||||
133
opencompass/configs/datasets/SimpleQA/simpleqa_gen_0283c3.py
Normal file
133
opencompass/configs/datasets/SimpleQA/simpleqa_gen_0283c3.py
Normal file
@ -0,0 +1,133 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.openicl.icl_evaluator import LMEvaluator
|
||||
from opencompass.datasets import SimpleQADataset, simpleqa_postprocess
|
||||
|
||||
GRADER_TEMPLATE = """
|
||||
Your job is to look at a question, a gold target, and a predicted answer, and then assign a grade of either ["CORRECT", "INCORRECT", "NOT_ATTEMPTED"].
|
||||
First, I will give examples of each grade, and then you will grade a new example.
|
||||
|
||||
|
||||
The following are examples of CORRECT predicted answers.
|
||||
```
|
||||
Question: What are the names of Barack Obama's children?
|
||||
Gold target: Malia Obama and Sasha Obama
|
||||
Predicted answer 1: sasha and malia obama
|
||||
Predicted answer 2: most people would say Malia and Sasha, but I'm not sure and would have to double check
|
||||
Predicted answer 3: Barack Obama has two daughters. Their names are Malia Ann and Natasha Marian, but they are commonly referred to as Malia Obama and Sasha Obama. Malia was born on July 4, 1998, and Sasha was born on June 10, 2001.
|
||||
```
|
||||
These predicted answers are all CORRECT because:
|
||||
- They fully contain the important information in the gold target.
|
||||
- They do not contain any information that contradicts the gold target.
|
||||
- Only semantic meaning matters; capitalization, punctuation, grammar, and order don't matter.
|
||||
- Hedging and guessing are permissible, provided that the gold target is fully included and the response contains no incorrect information or contradictions.
|
||||
|
||||
|
||||
The following are examples of INCORRECT predicted answers.
|
||||
```
|
||||
Question: What are the names of Barack Obama's children?
|
||||
Gold target: Malia and Sasha
|
||||
Predicted answer 1: Malia.
|
||||
Predicted answer 2: Malia, Sasha, and Susan.
|
||||
Predicted answer 3: Barack Obama does not have any children.
|
||||
Predicted answer 4: I think it's either Malia and Sasha. Or it could be Malia and Jackie. Or it could be Joey and Malia.
|
||||
Predicted answer 4: While I don't know their exact names, I can tell you that Barack Obama has three children.
|
||||
Predicted answer 5: It's possible you may mean Betsy and Olivia. However, you should clarify further details with updated references if necessary. Is that the correct answer?
|
||||
Predicted answer 6: It may be the case that Obama's child is named James. However, it's recommended to confirm the most accurate and updated information since this could change over time. This model may not always reflect the most current information.
|
||||
```
|
||||
These predicted answers are all INCORRECT because:
|
||||
- A factual statement in the answer contradicts the gold target. Incorrect statements that have some hedging (e.g., "it is possible that", "although i'm not sure, i think") are also considered incorrect.
|
||||
|
||||
|
||||
The following are examples of NOT_ATTEMPTED predicted answers.
|
||||
```
|
||||
Question: What are the names of Barack Obama's children?
|
||||
Gold target: Malia and Sasha
|
||||
Predicted answer 1: I don't know.
|
||||
Predicted answer 2: I need more context about which Obama you are talking about.
|
||||
Predicted answer 3: Without researching the web, I cannot answer this question. However, I can tell you that Barack Obama has two children.
|
||||
Predicted answer 4: Barack Obama has two children. I know that one of them is Malia, but I'm not sure about the other one.
|
||||
```
|
||||
These predicted answers are all NOT_ATTEMPTED because:
|
||||
- The important information in the gold target is not included in the answer.
|
||||
- No statements in the answer contradict the gold target.
|
||||
|
||||
|
||||
Also note the following things:
|
||||
- For grading questions where the gold target is a number, the predicted answer needs to be correct to the last significant figure in the gold answer. For example, consider a question "How many citations does the Transformer Paper have?" with gold target "120k".
|
||||
- Predicted answers "120k", "124k", and 115k" are all CORRECT.
|
||||
- Predicted answers "100k" and "113k" are INCORRECT.
|
||||
- Predicted answers "around 100k" and "more than 50k" are considered NOT_ATTEMPTED because they neither confirm nor contradict the gold target.
|
||||
- The gold target may contain more information than the question. In such cases, the predicted answer only needs to contain the information that is in the question.
|
||||
- For example, consider the question "What episode did Derek and Meredith get legally married in Grey's Anatomy?" with gold target "Season 7, Episode 20: White Wedding". Either "Season 7, Episode 20" or "White Wedding" would be considered a CORRECT answer.
|
||||
- Do not punish predicted answers if they omit information that would be clearly inferred from the question.
|
||||
- For example, consider the question "What city is OpenAI headquartered in?" and the gold target "San Francisco, California". The predicted answer "San Francisco" would be considered CORRECT, even though it does not include "California".
|
||||
- Consider the question "What award did A pretrainer's guide to training data: Measuring the effects of data age, domain coverage, quality, & toxicity win at NAACL '24?", the gold target is "Outstanding Paper Award". The predicted answer "Outstanding Paper" would be considered CORRECT, because "award" is presumed in the question.
|
||||
- For the question "What is the height of Jason Wei in meters?", the gold target is "1.73 m". The predicted answer "1.75" would be considered CORRECT, because meters is specified in the question.
|
||||
- For the question "What is the name of Barack Obama's wife?", the gold target is "Michelle Obama". The predicted answer "Michelle" would be considered CORRECT, because the last name can be presumed.
|
||||
- Do not punish for typos in people's name if it's clearly the same name.
|
||||
- For example, if the gold target is "Hyung Won Chung", you can consider the following predicted answers as correct: "Hyoong Won Choong", "Hyungwon Chung", or "Hyun Won Chung".
|
||||
|
||||
Grade the predicted answer of this new question as one of:
|
||||
A: CORRECT
|
||||
B: INCORRECT
|
||||
C: NOT_ATTEMPTED
|
||||
Just return the letters "A", "B", or "C", with no text around it.
|
||||
|
||||
Here is a new example. Simply reply with either CORRECT, INCORRECT, NOT ATTEMPTED. Don't apologize or correct yourself if there was a mistake; we are just trying to grade the answer.
|
||||
```
|
||||
Question: {problem}
|
||||
Gold target: {answer}
|
||||
Predicted answer: {prediction}
|
||||
```
|
||||
""".strip()
|
||||
|
||||
simpleqa_reader_cfg = dict(input_columns=['problem'], output_column='answer')
|
||||
|
||||
simpleqa_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(role='HUMAN', prompt="Question: {problem}\nLet's think step by step:"),
|
||||
],
|
||||
)),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=2048))
|
||||
|
||||
simpleqa_eval_cfg = dict(
|
||||
evaluator=dict(
|
||||
type=LMEvaluator,
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
begin=[
|
||||
dict(
|
||||
role='SYSTEM',
|
||||
fallback_role='HUMAN',
|
||||
prompt="You are a helpful assistant who evaluates the correctness and quality of models' outputs.")
|
||||
],
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt = GRADER_TEMPLATE
|
||||
),
|
||||
]),
|
||||
),
|
||||
dict_postprocessor=dict(type=simpleqa_postprocess),
|
||||
),
|
||||
pred_role='BOT',
|
||||
)
|
||||
|
||||
simpleqa_datasets = [
|
||||
dict(
|
||||
abbr='simpleqa',
|
||||
type=SimpleQADataset,
|
||||
path='opencompass/simpleqa',
|
||||
reader_cfg=simpleqa_reader_cfg,
|
||||
infer_cfg=simpleqa_infer_cfg,
|
||||
eval_cfg=simpleqa_eval_cfg,
|
||||
mode='singlescore',
|
||||
)
|
||||
]
|
||||
@ -0,0 +1,39 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets import Aime2024Dataset, MATHEvaluator, math_postprocess_v2
|
||||
|
||||
|
||||
aime2024_reader_cfg = dict(
|
||||
input_columns=['question'],
|
||||
output_column='answer'
|
||||
)
|
||||
|
||||
|
||||
aime2024_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(role='HUMAN', prompt='{question}\nRemember to put your final answer within \\boxed{}.'),
|
||||
],
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=2048)
|
||||
)
|
||||
|
||||
aime2024_eval_cfg = dict(
|
||||
evaluator=dict(type=MATHEvaluator, version='v2'), pred_postprocessor=dict(type=math_postprocess_v2)
|
||||
)
|
||||
|
||||
aime2024_datasets = [
|
||||
dict(
|
||||
abbr='aime2024',
|
||||
type=Aime2024Dataset,
|
||||
path='opencompass/aime2024',
|
||||
reader_cfg=aime2024_reader_cfg,
|
||||
infer_cfg=aime2024_infer_cfg,
|
||||
eval_cfg=aime2024_eval_cfg
|
||||
)
|
||||
]
|
||||
@ -0,0 +1,96 @@
|
||||
import os
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.openicl.icl_evaluator import AccEvaluator
|
||||
from opencompass.datasets import BBHDataset, BBHEvaluator, bbh_mcq_postprocess, BBHEvaluator_mcq
|
||||
|
||||
bbh_reader_cfg = dict(input_columns=['input'], output_column='target')
|
||||
|
||||
bbh_multiple_choice_sets = [
|
||||
'temporal_sequences',
|
||||
'disambiguation_qa',
|
||||
'date_understanding',
|
||||
'tracking_shuffled_objects_three_objects',
|
||||
'penguins_in_a_table',
|
||||
'geometric_shapes',
|
||||
'snarks',
|
||||
'ruin_names',
|
||||
'tracking_shuffled_objects_seven_objects',
|
||||
'tracking_shuffled_objects_five_objects',
|
||||
'logical_deduction_three_objects',
|
||||
'hyperbaton',
|
||||
'logical_deduction_five_objects',
|
||||
'logical_deduction_seven_objects',
|
||||
'movie_recommendation',
|
||||
'salient_translation_error_detection',
|
||||
'reasoning_about_colored_objects',
|
||||
]
|
||||
bbh_free_form_sets = [
|
||||
'multistep_arithmetic_two',
|
||||
'navigate',
|
||||
'dyck_languages',
|
||||
'word_sorting',
|
||||
'sports_understanding',
|
||||
'boolean_expressions',
|
||||
'object_counting',
|
||||
'formal_fallacies',
|
||||
'causal_judgement',
|
||||
'web_of_lies',
|
||||
]
|
||||
|
||||
bbh_datasets = []
|
||||
for _name in bbh_multiple_choice_sets:
|
||||
bbh_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt=
|
||||
f"Follow the given examples and answer the question.\n\nQuestion: {{input}}\n You must give your final answer by starting with 'So the answer is' "
|
||||
)
|
||||
])),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=512))
|
||||
bbh_eval_cfg = dict(
|
||||
evaluator=dict(type=BBHEvaluator_mcq),
|
||||
pred_role='BOT',
|
||||
pred_postprocessor=dict(type=bbh_mcq_postprocess),
|
||||
dataset_postprocessor=dict(type=bbh_mcq_postprocess))
|
||||
|
||||
bbh_datasets.append(
|
||||
dict(
|
||||
type=BBHDataset,
|
||||
path='opencompass/bbh',
|
||||
name=_name,
|
||||
abbr='bbh-' + _name,
|
||||
reader_cfg=bbh_reader_cfg,
|
||||
infer_cfg=bbh_infer_cfg.copy(),
|
||||
eval_cfg=bbh_eval_cfg.copy()))
|
||||
|
||||
for _name in bbh_free_form_sets:
|
||||
|
||||
bbh_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt=
|
||||
f"Follow the given examples and answer the question.\n\nQuestion: {{input}}\n You must give your final answer by starting with 'So the answer is' "
|
||||
)
|
||||
])),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=512))
|
||||
bbh_eval_cfg = dict(evaluator=dict(type=BBHEvaluator), pred_role='BOT')
|
||||
|
||||
bbh_datasets.append(
|
||||
dict(
|
||||
type=BBHDataset,
|
||||
path='opencompass/bbh',
|
||||
name=_name,
|
||||
abbr='bbh-' + _name,
|
||||
reader_cfg=bbh_reader_cfg,
|
||||
infer_cfg=bbh_infer_cfg.copy(),
|
||||
eval_cfg=bbh_eval_cfg.copy()))
|
||||
@ -0,0 +1,96 @@
|
||||
import os
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.openicl.icl_evaluator import AccEvaluator
|
||||
from opencompass.datasets import BBHDataset, BBHEvaluator, bbh_mcq_postprocess, BBHEvaluator_mcq
|
||||
|
||||
bbh_reader_cfg = dict(input_columns=['input'], output_column='target')
|
||||
|
||||
bbh_multiple_choice_sets = [
|
||||
'temporal_sequences',
|
||||
'disambiguation_qa',
|
||||
'date_understanding',
|
||||
'tracking_shuffled_objects_three_objects',
|
||||
'penguins_in_a_table',
|
||||
'geometric_shapes',
|
||||
'snarks',
|
||||
'ruin_names',
|
||||
'tracking_shuffled_objects_seven_objects',
|
||||
'tracking_shuffled_objects_five_objects',
|
||||
'logical_deduction_three_objects',
|
||||
'hyperbaton',
|
||||
'logical_deduction_five_objects',
|
||||
'logical_deduction_seven_objects',
|
||||
'movie_recommendation',
|
||||
'salient_translation_error_detection',
|
||||
'reasoning_about_colored_objects',
|
||||
]
|
||||
bbh_free_form_sets = [
|
||||
'multistep_arithmetic_two',
|
||||
'navigate',
|
||||
'dyck_languages',
|
||||
'word_sorting',
|
||||
'sports_understanding',
|
||||
'boolean_expressions',
|
||||
'object_counting',
|
||||
'formal_fallacies',
|
||||
'causal_judgement',
|
||||
'web_of_lies',
|
||||
]
|
||||
|
||||
bbh_datasets = []
|
||||
for _name in bbh_multiple_choice_sets:
|
||||
bbh_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt=
|
||||
f"Question: {{input}}\n You must give your final answer by starting with 'So the answer is' "
|
||||
)
|
||||
])),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=512))
|
||||
bbh_eval_cfg = dict(
|
||||
evaluator=dict(type=BBHEvaluator_mcq),
|
||||
pred_role='BOT',
|
||||
pred_postprocessor=dict(type=bbh_mcq_postprocess),
|
||||
dataset_postprocessor=dict(type=bbh_mcq_postprocess))
|
||||
|
||||
bbh_datasets.append(
|
||||
dict(
|
||||
type=BBHDataset,
|
||||
path='opencompass/bbh',
|
||||
name=_name,
|
||||
abbr='bbh-' + _name,
|
||||
reader_cfg=bbh_reader_cfg,
|
||||
infer_cfg=bbh_infer_cfg.copy(),
|
||||
eval_cfg=bbh_eval_cfg.copy()))
|
||||
|
||||
for _name in bbh_free_form_sets:
|
||||
|
||||
bbh_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt=
|
||||
f"Follow the given examples and answer the question.\n\nQuestion: {{input}}\n You must give your final answer by starting with 'So the answer is' "
|
||||
)
|
||||
])),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=512))
|
||||
bbh_eval_cfg = dict(evaluator=dict(type=BBHEvaluator), pred_role='BOT')
|
||||
|
||||
bbh_datasets.append(
|
||||
dict(
|
||||
type=BBHDataset,
|
||||
path='opencompass/bbh',
|
||||
name=_name,
|
||||
abbr='bbh-' + _name,
|
||||
reader_cfg=bbh_reader_cfg,
|
||||
infer_cfg=bbh_infer_cfg.copy(),
|
||||
eval_cfg=bbh_eval_cfg.copy()))
|
||||
@ -0,0 +1,39 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets import CMOFibDataset, MATHEvaluator, math_postprocess_v2
|
||||
|
||||
|
||||
cmo_fib_reader_cfg = dict(
|
||||
input_columns=['question'],
|
||||
output_column='answer'
|
||||
)
|
||||
|
||||
|
||||
cmo_fib_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(role='HUMAN', prompt='{question}\n你需要讲最终答案写入\\boxed{}.'),
|
||||
],
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=2048)
|
||||
)
|
||||
|
||||
cmo_fib_eval_cfg = dict(
|
||||
evaluator=dict(type=MATHEvaluator, version='v2'), pred_postprocessor=dict(type=math_postprocess_v2)
|
||||
)
|
||||
|
||||
cmo_fib_datasets = [
|
||||
dict(
|
||||
abbr='cmo_fib',
|
||||
type=CMOFibDataset,
|
||||
path='opencompass/cmo_fib',
|
||||
reader_cfg=cmo_fib_reader_cfg,
|
||||
infer_cfg=cmo_fib_infer_cfg,
|
||||
eval_cfg=cmo_fib_eval_cfg
|
||||
)
|
||||
]
|
||||
@ -0,0 +1,52 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets import GPQADataset, GPQA_Simple_Eval_postprocess, GPQAEvaluator
|
||||
|
||||
# openai_simple_eval prompt
|
||||
align_prompt = """
|
||||
Answer the following multiple choice question. The last line of your response should be of the following format: 'ANSWER: $LETTER' (without quotes) where LETTER is one of ABCD.
|
||||
|
||||
{question}
|
||||
|
||||
A) {A}
|
||||
B) {B}
|
||||
C) {C}
|
||||
D) {D}
|
||||
""".strip()
|
||||
|
||||
gpqa_reader_cfg = dict(
|
||||
input_columns=['question', 'A', 'B', 'C', 'D'],
|
||||
output_column='answer')
|
||||
|
||||
gpqa_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(role='HUMAN', prompt=align_prompt),
|
||||
], )),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer))
|
||||
|
||||
gpqa_eval_cfg = dict(evaluator=dict(type=GPQAEvaluator),
|
||||
pred_postprocessor=dict(type=GPQA_Simple_Eval_postprocess))
|
||||
|
||||
gpqa_datasets = []
|
||||
gpqa_subsets = {
|
||||
# 'extended': 'gpqa_extended.csv',
|
||||
# 'main': 'gpqa_main.csv',
|
||||
'diamond': 'gpqa_diamond.csv'
|
||||
}
|
||||
|
||||
for split in list(gpqa_subsets.keys()):
|
||||
gpqa_datasets.append(
|
||||
dict(
|
||||
abbr='GPQA_' + split,
|
||||
type=GPQADataset,
|
||||
path='./data/gpqa/',
|
||||
name=gpqa_subsets[split],
|
||||
reader_cfg=gpqa_reader_cfg,
|
||||
infer_cfg=gpqa_infer_cfg,
|
||||
eval_cfg=gpqa_eval_cfg)
|
||||
)
|
||||
@ -0,0 +1,37 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets import GSM8KDataset, gsm8k_postprocess, gsm8k_dataset_postprocess, Gsm8kEvaluator
|
||||
from opencompass.datasets import MATHEvaluator, math_postprocess_v2
|
||||
|
||||
gsm8k_reader_cfg = dict(input_columns=['question'], output_column='answer')
|
||||
|
||||
gsm8k_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(role='HUMAN', prompt='{question}\nPlease put your final answer within \\boxed{}.'),
|
||||
],
|
||||
),
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=512),
|
||||
)
|
||||
|
||||
gsm8k_eval_cfg = dict(
|
||||
evaluator=dict(type=MATHEvaluator, version='v2'),
|
||||
pred_postprocessor=dict(type=math_postprocess_v2),
|
||||
dataset_postprocessor=dict(type=gsm8k_dataset_postprocess),
|
||||
)
|
||||
|
||||
gsm8k_datasets = [
|
||||
dict(
|
||||
abbr='gsm8k',
|
||||
type=GSM8KDataset,
|
||||
path='opencompass/gsm8k',
|
||||
reader_cfg=gsm8k_reader_cfg,
|
||||
infer_cfg=gsm8k_infer_cfg,
|
||||
eval_cfg=gsm8k_eval_cfg,
|
||||
)
|
||||
]
|
||||
@ -0,0 +1,37 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets import GSM8KDataset, gsm8k_postprocess, gsm8k_dataset_postprocess, Gsm8kEvaluator
|
||||
from opencompass.datasets import MATHEvaluator, math_postprocess_v2
|
||||
|
||||
gsm8k_reader_cfg = dict(input_columns=['question'], output_column='answer')
|
||||
|
||||
gsm8k_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(role='HUMAN', prompt='{question}\nPlease reason step by step, and put your final answer within \\boxed{}.'),
|
||||
],
|
||||
),
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=2048),
|
||||
)
|
||||
|
||||
gsm8k_eval_cfg = dict(
|
||||
evaluator=dict(type=MATHEvaluator, version='v2'),
|
||||
pred_postprocessor=dict(type=math_postprocess_v2),
|
||||
dataset_postprocessor=dict(type=gsm8k_dataset_postprocess),
|
||||
)
|
||||
|
||||
gsm8k_datasets = [
|
||||
dict(
|
||||
abbr='gsm8k',
|
||||
type=GSM8KDataset,
|
||||
path='opencompass/gsm8k',
|
||||
reader_cfg=gsm8k_reader_cfg,
|
||||
infer_cfg=gsm8k_infer_cfg,
|
||||
eval_cfg=gsm8k_eval_cfg,
|
||||
)
|
||||
]
|
||||
@ -0,0 +1,38 @@
|
||||
# THIS SHALL ALSO BE DEPRECATED
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets import HumanevalDataset, HumanEvalPlusEvaluator, humaneval_postprocess_v2
|
||||
|
||||
humaneval_plus_reader_cfg = dict(
|
||||
input_columns=['prompt'], output_column='task_id', train_split='test')
|
||||
|
||||
# TODO: allow empty output-column
|
||||
humaneval_plus_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt='Read the following function signature and docstring, and fully implement the function described. Your response should only contain the code for this function.\n{prompt}'
|
||||
),
|
||||
])),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=512))
|
||||
|
||||
humaneval_plus_eval_cfg = dict(
|
||||
evaluator=dict(type=HumanEvalPlusEvaluator),
|
||||
pred_role='BOT',
|
||||
k=[1, 10, 100], # the parameter only for humaneval
|
||||
pred_postprocessor=dict(type=humaneval_postprocess_v2),
|
||||
)
|
||||
|
||||
humaneval_plus_datasets = [
|
||||
dict(
|
||||
abbr='humaneval_plus',
|
||||
type=HumanevalDataset,
|
||||
path='opencompass/humaneval',
|
||||
reader_cfg=humaneval_plus_reader_cfg,
|
||||
infer_cfg=humaneval_plus_infer_cfg,
|
||||
eval_cfg=humaneval_plus_eval_cfg)
|
||||
]
|
||||
@ -0,0 +1,40 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets import HumanevalXDataset, HumanevalXEvaluator
|
||||
|
||||
humanevalx_reader_cfg = dict(
|
||||
input_columns=['prompt'], output_column='declaration', train_split='test')
|
||||
|
||||
humanevalx_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
prompt='Read the following function signature and docstring, and fully implement the function described. Your response should only contain the code for this function.\n{prompt}'), retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=1024))
|
||||
|
||||
humanevalx_eval_cfg_dict = {
|
||||
lang : dict(
|
||||
evaluator=dict(
|
||||
type=HumanevalXEvaluator,
|
||||
language=lang,
|
||||
ip_address=
|
||||
'localhost', # replace to your code_eval_server ip_address, port
|
||||
port=5001), # refer to https://opencompass.readthedocs.io/en/latest/advanced_guides/code_eval_service.html to launch a server
|
||||
pred_role='BOT')
|
||||
for lang in ['python', 'cpp', 'go', 'java', 'js'] # do not support rust now
|
||||
}
|
||||
|
||||
# Please download the needed `xx.jsonl.gz` from
|
||||
# https://github.com/THUDM/CodeGeeX2/tree/main/benchmark/humanevalx
|
||||
# and move them into `data/humanevalx/` folder
|
||||
humanevalx_datasets = [
|
||||
dict(
|
||||
type=HumanevalXDataset,
|
||||
abbr=f'humanevalx-{lang}',
|
||||
language=lang,
|
||||
path='./data/humanevalx',
|
||||
reader_cfg=humanevalx_reader_cfg,
|
||||
infer_cfg=humanevalx_infer_cfg,
|
||||
eval_cfg=humanevalx_eval_cfg_dict[lang])
|
||||
for lang in ['python', 'cpp', 'go', 'java', 'js']
|
||||
]
|
||||
@ -0,0 +1,59 @@
|
||||
from opencompass.datasets.korbench.korbench import korbenchDataset, korbenchEvaluator
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
korbench_mixed_datasets = []
|
||||
|
||||
categories = ["Multi-Q", "Multi-R", "Multi-RQ"] # Define available modes for mixed mode
|
||||
|
||||
for category in categories:
|
||||
# Prompt template
|
||||
prompt_template = dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
begin=[
|
||||
dict(
|
||||
role="HUMAN",
|
||||
prompt=""
|
||||
)
|
||||
],
|
||||
round=[
|
||||
dict(
|
||||
role="HUMAN",
|
||||
prompt="{prompt}" # f-string
|
||||
)
|
||||
]
|
||||
)
|
||||
)
|
||||
|
||||
# Reader configuration
|
||||
reader_cfg = dict(
|
||||
input_columns=["prompt"],
|
||||
output_column="answer",
|
||||
)
|
||||
|
||||
# Inference configuration
|
||||
infer_cfg = dict(
|
||||
prompt_template=prompt_template,
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=1024),
|
||||
)
|
||||
|
||||
# Evaluation configuration
|
||||
eval_cfg = dict(
|
||||
evaluator=dict(type=korbenchEvaluator),
|
||||
pred_role="BOT",
|
||||
)
|
||||
|
||||
korbench_dataset = dict(
|
||||
type=korbenchDataset,
|
||||
abbr=f"korbench_mixed_{category}",
|
||||
path="opencompass/korbench",
|
||||
category=category,
|
||||
mode='mixed',
|
||||
reader_cfg=reader_cfg,
|
||||
infer_cfg=infer_cfg,
|
||||
eval_cfg=eval_cfg,
|
||||
)
|
||||
|
||||
korbench_mixed_datasets.append(korbench_dataset)
|
||||
@ -0,0 +1,60 @@
|
||||
from opencompass.datasets.korbench.korbench import korbenchDataset, korbenchEvaluator
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
|
||||
categories = ["cipher", "counterfactual", "logic", "operation", "puzzle"]
|
||||
|
||||
korbench_0shot_single_datasets = []
|
||||
|
||||
for category in categories:
|
||||
# Prompt template
|
||||
prompt_template = dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
begin=[
|
||||
dict(
|
||||
role="HUMAN",
|
||||
prompt=""
|
||||
)
|
||||
],
|
||||
round=[
|
||||
dict(
|
||||
role="HUMAN",
|
||||
prompt="{prompt}" # f-string
|
||||
)
|
||||
]
|
||||
)
|
||||
)
|
||||
|
||||
# Reader configuration
|
||||
reader_cfg = dict(
|
||||
input_columns=["prompt"],
|
||||
output_column="answer",
|
||||
)
|
||||
|
||||
# Inference configuration
|
||||
infer_cfg = dict(
|
||||
prompt_template=prompt_template,
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=1024),
|
||||
)
|
||||
|
||||
# Evaluation configuration
|
||||
eval_cfg = dict(
|
||||
evaluator=dict(type=korbenchEvaluator),
|
||||
pred_role="BOT",
|
||||
)
|
||||
|
||||
korbench_dataset = dict(
|
||||
type=korbenchDataset,
|
||||
abbr=f"korbench_{category}",
|
||||
path="opencompass/korbench",
|
||||
mode='0_shot',
|
||||
category=category,
|
||||
reader_cfg=reader_cfg,
|
||||
infer_cfg=infer_cfg,
|
||||
eval_cfg=eval_cfg,
|
||||
)
|
||||
|
||||
korbench_0shot_single_datasets.append(korbench_dataset)
|
||||
@ -0,0 +1,61 @@
|
||||
from opencompass.datasets.korbench.korbench import korbenchDataset, korbenchEvaluator
|
||||
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
|
||||
categories = ["cipher", "counterfactual", "logic", "operation", "puzzle"]
|
||||
|
||||
korbench_3shot_single_datasets = []
|
||||
|
||||
for category in categories:
|
||||
# Prompt template
|
||||
prompt_template = dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
begin=[
|
||||
dict(
|
||||
role="HUMAN",
|
||||
prompt=""
|
||||
)
|
||||
],
|
||||
round=[
|
||||
dict(
|
||||
role="HUMAN",
|
||||
prompt="{prompt}" # f-string
|
||||
)
|
||||
]
|
||||
)
|
||||
)
|
||||
|
||||
# Reader configuration
|
||||
reader_cfg = dict(
|
||||
input_columns=["prompt"],
|
||||
output_column="answer",
|
||||
)
|
||||
|
||||
# Inference configuration
|
||||
infer_cfg = dict(
|
||||
prompt_template=prompt_template,
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=1024),
|
||||
)
|
||||
|
||||
# Evaluation configuration
|
||||
eval_cfg = dict(
|
||||
evaluator=dict(type=korbenchEvaluator),
|
||||
pred_role="BOT",
|
||||
)
|
||||
|
||||
korbench_dataset = dict(
|
||||
type=korbenchDataset,
|
||||
abbr=f"korbench_{category}",
|
||||
path="opencompass/korbench",
|
||||
mode='3_shot',
|
||||
category=category,
|
||||
reader_cfg=reader_cfg,
|
||||
infer_cfg=infer_cfg,
|
||||
eval_cfg=eval_cfg,
|
||||
)
|
||||
|
||||
korbench_3shot_single_datasets.append(korbench_dataset)
|
||||
71
opencompass/configs/datasets/korbench/readme.md
Normal file
71
opencompass/configs/datasets/korbench/readme.md
Normal file
@ -0,0 +1,71 @@
|
||||
# KOR-Bench: Benchmarking Language Models on Knowledge-Orthogonal Reasoning Tasks
|
||||
|
||||
KOR-Bench is a dataset designed to evaluate large language models (LLMs) on tasks that require reasoning independent of prior knowledge. Created to assess reasoning and planning abilities, KOR-Bench introduces rule-based tasks that minimize the influence of pretrained knowledge, enabling a focused evaluation of intrinsic model capabilities.
|
||||
|
||||
## Overview
|
||||
|
||||
### Purpose
|
||||
|
||||
Large language models, such as GPT-4 and Claude, excel in knowledge-based tasks but face challenges in applying reasoning skills to unfamiliar scenarios. KOR-Bench is built to evaluate such reasoning capabilities across five categories:
|
||||
- **Operation**: Arithmetic and logical operations.
|
||||
- **Logic**: Complex deductive and inductive reasoning.
|
||||
- **Cipher**: Code-breaking and pattern discovery.
|
||||
- **Puzzle**: Problem-solving with creative and logical reasoning.
|
||||
- **Counterfactual**: Hypothetical reasoning in alternate scenarios.
|
||||
|
||||
### Dataset Construction
|
||||
|
||||
KOR-Bench tasks are designed with novel rules and configurations, ensuring no reliance on pretrained knowledge. Each task includes:
|
||||
- **Rules**: Custom rule sets to guide reasoning.
|
||||
- **Questions**: Carefully crafted problems that require the application of rules.
|
||||
- **Evaluation Scenarios**: Zero-shot, three-shot, and subquestion-specific configurations.
|
||||
|
||||
The dataset is structured to assess multistep reasoning, pattern recognition, and adaptability to new rules.
|
||||
|
||||
### Dataset Access
|
||||
|
||||
KOR-Bench is publicly available with detailed usage instructions in the [GitHub Repository](https://github.com/KOR-Bench/KOR-Bench). Download the dataset and leverage predefined evaluation scripts or customize your own.
|
||||
|
||||
### Evaluation
|
||||
|
||||
1. Install dependencies and configure your environment.
|
||||
2. Run evaluations using `opencompass configs/eval_korbench.py` to assess LLM performance.
|
||||
3. Analyze model performance across various reasoning tasks.
|
||||
|
||||
### Example Command
|
||||
```bash
|
||||
opencompass configs/eval_korbench.py
|
||||
```
|
||||
|
||||
## Baselines and Results
|
||||
KOR-Bench includes baseline results for leading LLMs evaluated across various configurations, including zero-shot (gen) and few-shot modes. Below is a summary of the results.
|
||||
| dataset | version | metric | mode | internlm2_5-7b-chat-turbomind | internlm2_5-1_8b-chat-turbomind | llama-3_1-8b-instruct-turbomind | glm-4-9b-chat-turbomind | gemma-2-9b-it-turbomind |
|
||||
|---------|---------|--------|------|--------------------------------|---------------------------------|---------------------------------|--------------------------|--------------------------|
|
||||
| korbench_mixed_Multi-Q | 21f998 | accuracy | gen | 0.60 | 0.20 | 9.60 | 8.70 | 7.80 |
|
||||
| korbench_mixed_Multi-R | 21f998 | accuracy | gen | 1.70 | 0.10 | 8.80 | 12.10 | 9.80 |
|
||||
| korbench_mixed_Multi-RQ | 21f998 | accuracy | gen | 1.50 | 0.10 | 6.40 | 8.60 | 6.00 |
|
||||
| korbench_cipher | 21f998 | accuracy | gen | 8.80 | 0.80 | 14.00 | 6.80 | 6.40 |
|
||||
| korbench_counterfactual | 21f998 | accuracy | gen | 83.60 | 17.20 | 88.80 | 90.40 | 87.60 |
|
||||
| korbench_logic | 21f998 | accuracy | gen | 8.40 | 3.60 | 37.60 | 38.80 | 40.80 |
|
||||
| korbench_operation | 21f998 | accuracy | gen | 56.00 | 25.20 | 68.40 | 63.60 | 67.60 |
|
||||
| korbench_puzzle | 21f998 | accuracy | gen | 3.60 | 0.00 | 3.20 | 3.20 | 5.60 |
|
||||
| korbench_cipher | 21f998 | accuracy | fewshot | 8.40 | 3.20 | 9.60 | 9.20 | 9.60 |
|
||||
| korbench_counterfactual | 21f998 | accuracy | fewshot | 87.60 | 58.00 | 23.60 | 89.60 | 84.40 |
|
||||
| korbench_logic | 21f998 | accuracy | fewshot | 45.20 | 19.60 | 24.40 | 38.40 | 54.00 |
|
||||
| korbench_operation | 21f998 | accuracy | fewshot | 24.80 | 11.20 | 73.20 | 67.20 | 23.20 |
|
||||
| korbench_puzzle | 21f998 | accuracy | fewshot | 4.80 | 2.40 | 1.60 | 3.60 | 6.80 |
|
||||
|
||||
### Citation
|
||||
|
||||
**BibTeX:**
|
||||
```bibtex
|
||||
@misc{ma2024korbenchbenchmarkinglanguagemodels,
|
||||
title={KOR-Bench: Benchmarking Language Models on Knowledge-Orthogonal Reasoning Tasks},
|
||||
author={Kaijing Ma and Xinrun Du and Yunran Wang and Haoran Zhang and Zhoufutu Wen and Xingwei Qu and Jian Yang and Jiaheng Liu and Minghao Liu and Xiang Yue and Wenhao Huang and Ge Zhang},
|
||||
year={2024},
|
||||
eprint={2410.06526},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.DB},
|
||||
url={https://arxiv.org/abs/2410.06526},
|
||||
}
|
||||
```
|
||||
@ -0,0 +1,165 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets import (
|
||||
LCBCodeGenerationDataset,
|
||||
LCBCodeExecutionDataset,
|
||||
LCBTestOutputPredictionDataset,
|
||||
LCBCodeGenerationEvaluator,
|
||||
LCBCodeExecutionEvaluator,
|
||||
LCBTestOutputEvaluator
|
||||
)
|
||||
from opencompass.datasets.livecodebench import TestOutputPromptConstants
|
||||
|
||||
|
||||
lcb_code_generation_reader_cfg = dict(
|
||||
input_columns=[
|
||||
'question_content',
|
||||
'format_prompt',
|
||||
],
|
||||
# output_column='evaluation_sample',
|
||||
output_column='question_id',
|
||||
)
|
||||
|
||||
SYSTEM_MESSAGE_GENERIC = f'You are an expert Python programmer. You will be given a question (problem specification) and will generate a correct Python program that matches the specification and passes all tests. You will NOT return anything except for the program.'
|
||||
|
||||
prompt_template = '### Question:\n{question_content}\n\n{format_prompt}' + \
|
||||
'### Answer: (use the provided format with backticks)\n\n'
|
||||
|
||||
|
||||
# Code Generation Tasks
|
||||
lcb_code_generation_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt=prompt_template
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=1024)
|
||||
)
|
||||
|
||||
lcb_code_generation_eval_cfg = dict(
|
||||
evaluator=dict(
|
||||
type=LCBCodeGenerationEvaluator,
|
||||
num_process_evaluate=4,
|
||||
timeout=6,
|
||||
release_version='release_v4',
|
||||
),
|
||||
pred_role='BOT',
|
||||
)
|
||||
|
||||
LCBCodeGeneration_dataset = dict(
|
||||
type=LCBCodeGenerationDataset,
|
||||
abbr='lcb_code_generation_v4',
|
||||
path='opencompass/code_generation_lite',
|
||||
reader_cfg=lcb_code_generation_reader_cfg,
|
||||
infer_cfg=lcb_code_generation_infer_cfg,
|
||||
eval_cfg=lcb_code_generation_eval_cfg,
|
||||
release_version='release_v4',
|
||||
)
|
||||
|
||||
# Code Execution Dataset
|
||||
lcb_code_execution_reader_cfg = dict(
|
||||
input_columns=[
|
||||
'prompt',
|
||||
],
|
||||
output_column='evaluation_sample',
|
||||
)
|
||||
|
||||
lcb_code_execution_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
begin=[
|
||||
dict(
|
||||
role='SYSTEM',
|
||||
prompt='You are an expert at Python programming, code execution, test case generation, and fuzzing.'
|
||||
),
|
||||
],
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt='{prompt}'
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=1024)
|
||||
)
|
||||
|
||||
lcb_code_execution_eval_cfg = dict(
|
||||
evaluator=dict(
|
||||
type=LCBCodeExecutionEvaluator,
|
||||
),
|
||||
pred_role='BOT',
|
||||
)
|
||||
|
||||
LCBCodeExecution_dataset = dict(
|
||||
type=LCBCodeExecutionDataset,
|
||||
abbr='lcb_code_execution',
|
||||
path='opencompass/execution-v2',
|
||||
reader_cfg=lcb_code_execution_reader_cfg,
|
||||
infer_cfg=lcb_code_execution_infer_cfg,
|
||||
eval_cfg=lcb_code_execution_eval_cfg,
|
||||
)
|
||||
|
||||
# TestOuputput Dataset
|
||||
lcb_test_output_reader_cfg = dict(
|
||||
input_columns=[
|
||||
'prompt',
|
||||
],
|
||||
output_column='evaluation_sample',
|
||||
)
|
||||
|
||||
system_prompt = 'You are an expert Python programmer. You will be given a question (problem specification) and will generate a correct Python program that matches the specification and passes all tests. You will NOT return anything except for the program.'
|
||||
|
||||
lcb_test_output_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
# begin=[
|
||||
# dict(
|
||||
# role='SYSTEM',
|
||||
# prompt=system_prompt
|
||||
# ),
|
||||
# ],
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt='{prompt}'
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=1024)
|
||||
)
|
||||
|
||||
lcb_test_output_eval_cfg = dict(
|
||||
evaluator=dict(
|
||||
type=LCBTestOutputEvaluator,
|
||||
),
|
||||
pred_role='BOT',
|
||||
)
|
||||
|
||||
LCBTestOutput_dataset = dict(
|
||||
type=LCBTestOutputPredictionDataset,
|
||||
abbr='lcb_test_output',
|
||||
path='opencompass/test_generation',
|
||||
reader_cfg=lcb_test_output_reader_cfg,
|
||||
infer_cfg=lcb_test_output_infer_cfg,
|
||||
eval_cfg=lcb_test_output_eval_cfg,
|
||||
)
|
||||
|
||||
LCB_datasets = [
|
||||
LCBCodeGeneration_dataset,
|
||||
# LCBCodeExecution_dataset,
|
||||
# LCBTestOutput_dataset,
|
||||
]
|
||||
@ -0,0 +1,165 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets import (
|
||||
LCBCodeGenerationDataset,
|
||||
LCBCodeExecutionDataset,
|
||||
LCBTestOutputPredictionDataset,
|
||||
LCBCodeGenerationEvaluator,
|
||||
LCBCodeExecutionEvaluator,
|
||||
LCBTestOutputEvaluator
|
||||
)
|
||||
from opencompass.datasets.livecodebench import TestOutputPromptConstants
|
||||
|
||||
|
||||
lcb_code_generation_reader_cfg = dict(
|
||||
input_columns=[
|
||||
'question_content',
|
||||
'format_prompt',
|
||||
],
|
||||
# output_column='evaluation_sample',
|
||||
output_column='question_id',
|
||||
)
|
||||
|
||||
SYSTEM_MESSAGE_GENERIC = f'You are an expert Python programmer. You will be given a question (problem specification) and will generate a correct Python program that matches the specification and passes all tests. You will NOT return anything except for the program.'
|
||||
|
||||
prompt_template = '### Question:\n{question_content}\n\n{format_prompt}' + \
|
||||
'### Answer: (use the provided format with backticks)\n\n'
|
||||
|
||||
|
||||
# Code Generation Tasks
|
||||
lcb_code_generation_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt=prompt_template
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=1024)
|
||||
)
|
||||
|
||||
lcb_code_generation_eval_cfg = dict(
|
||||
evaluator=dict(
|
||||
type=LCBCodeGenerationEvaluator,
|
||||
num_process_evaluate=4,
|
||||
timeout=6,
|
||||
release_version='release_split_v4',
|
||||
),
|
||||
pred_role='BOT',
|
||||
)
|
||||
|
||||
LCBCodeGeneration_dataset = dict(
|
||||
type=LCBCodeGenerationDataset,
|
||||
abbr='lcb_code_generation_split_v4',
|
||||
path='opencompass/code_generation_lite',
|
||||
reader_cfg=lcb_code_generation_reader_cfg,
|
||||
infer_cfg=lcb_code_generation_infer_cfg,
|
||||
eval_cfg=lcb_code_generation_eval_cfg,
|
||||
release_version='release_split_v4',
|
||||
)
|
||||
|
||||
# Code Execution Dataset
|
||||
lcb_code_execution_reader_cfg = dict(
|
||||
input_columns=[
|
||||
'prompt',
|
||||
],
|
||||
output_column='evaluation_sample',
|
||||
)
|
||||
|
||||
lcb_code_execution_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
begin=[
|
||||
dict(
|
||||
role='SYSTEM',
|
||||
prompt='You are an expert at Python programming, code execution, test case generation, and fuzzing.'
|
||||
),
|
||||
],
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt='{prompt}'
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=1024)
|
||||
)
|
||||
|
||||
lcb_code_execution_eval_cfg = dict(
|
||||
evaluator=dict(
|
||||
type=LCBCodeExecutionEvaluator,
|
||||
),
|
||||
pred_role='BOT',
|
||||
)
|
||||
|
||||
LCBCodeExecution_dataset = dict(
|
||||
type=LCBCodeExecutionDataset,
|
||||
abbr='lcb_code_execution',
|
||||
path='opencompass/execution-v2',
|
||||
reader_cfg=lcb_code_execution_reader_cfg,
|
||||
infer_cfg=lcb_code_execution_infer_cfg,
|
||||
eval_cfg=lcb_code_execution_eval_cfg,
|
||||
)
|
||||
|
||||
# TestOuputput Dataset
|
||||
lcb_test_output_reader_cfg = dict(
|
||||
input_columns=[
|
||||
'prompt',
|
||||
],
|
||||
output_column='evaluation_sample',
|
||||
)
|
||||
|
||||
system_prompt = 'You are an expert Python programmer. You will be given a question (problem specification) and will generate a correct Python program that matches the specification and passes all tests. You will NOT return anything except for the program.'
|
||||
|
||||
lcb_test_output_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
# begin=[
|
||||
# dict(
|
||||
# role='SYSTEM',
|
||||
# prompt=system_prompt
|
||||
# ),
|
||||
# ],
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt='{prompt}'
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=1024)
|
||||
)
|
||||
|
||||
lcb_test_output_eval_cfg = dict(
|
||||
evaluator=dict(
|
||||
type=LCBTestOutputEvaluator,
|
||||
),
|
||||
pred_role='BOT',
|
||||
)
|
||||
|
||||
LCBTestOutput_dataset = dict(
|
||||
type=LCBTestOutputPredictionDataset,
|
||||
abbr='lcb_test_output',
|
||||
path='opencompass/test_generation',
|
||||
reader_cfg=lcb_test_output_reader_cfg,
|
||||
infer_cfg=lcb_test_output_infer_cfg,
|
||||
eval_cfg=lcb_test_output_eval_cfg,
|
||||
)
|
||||
|
||||
LCB_datasets = [
|
||||
LCBCodeGeneration_dataset,
|
||||
# LCBCodeExecution_dataset,
|
||||
# LCBTestOutput_dataset,
|
||||
]
|
||||
@ -0,0 +1,164 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets import (
|
||||
LCBCodeGenerationDataset,
|
||||
LCBCodeExecutionDataset,
|
||||
LCBTestOutputPredictionDataset,
|
||||
LCBCodeGenerationEvaluator,
|
||||
LCBCodeExecutionEvaluator,
|
||||
LCBTestOutputEvaluator
|
||||
)
|
||||
from opencompass.datasets.livecodebench import TestOutputPromptConstants
|
||||
|
||||
|
||||
lcb_code_generation_reader_cfg = dict(
|
||||
input_columns=[
|
||||
'question_content',
|
||||
'format_prompt',
|
||||
],
|
||||
# output_column='evaluation_sample',
|
||||
output_column='question_id',
|
||||
)
|
||||
|
||||
SYSTEM_MESSAGE_GENERIC = f'You are an expert Python programmer. You will be given a question (problem specification) and will generate a correct Python program that matches the specification and passes all tests. You will NOT return anything except for the program.'
|
||||
|
||||
prompt_template = '### Question:\n{question_content}\n\n{format_prompt}' + \
|
||||
'### Answer: (use the provided format with backticks)\n\n'
|
||||
|
||||
|
||||
# Code Generation Tasks
|
||||
lcb_code_generation_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt=prompt_template
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=1024)
|
||||
)
|
||||
|
||||
lcb_code_generation_eval_cfg = dict(
|
||||
evaluator=dict(
|
||||
type=LCBCodeGenerationEvaluator,
|
||||
num_process_evaluate=4,
|
||||
timeout=6,
|
||||
),
|
||||
pred_role='BOT',
|
||||
)
|
||||
|
||||
LCBCodeGeneration_dataset = dict(
|
||||
type=LCBCodeGenerationDataset,
|
||||
abbr='lcb_code_generation_v1',
|
||||
path='opencompass/code_generation_lite',
|
||||
reader_cfg=lcb_code_generation_reader_cfg,
|
||||
infer_cfg=lcb_code_generation_infer_cfg,
|
||||
eval_cfg=lcb_code_generation_eval_cfg,
|
||||
release_version='release_v1',
|
||||
)
|
||||
|
||||
# Code Execution Dataset
|
||||
lcb_code_execution_reader_cfg = dict(
|
||||
input_columns=[
|
||||
'prompt',
|
||||
],
|
||||
output_column='evaluation_sample',
|
||||
)
|
||||
|
||||
lcb_code_execution_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
begin=[
|
||||
dict(
|
||||
role='SYSTEM',
|
||||
prompt='You are an expert at Python programming, code execution, test case generation, and fuzzing.'
|
||||
),
|
||||
],
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt='{prompt}'
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=1024)
|
||||
)
|
||||
|
||||
lcb_code_execution_eval_cfg = dict(
|
||||
evaluator=dict(
|
||||
type=LCBCodeExecutionEvaluator,
|
||||
),
|
||||
pred_role='BOT',
|
||||
)
|
||||
|
||||
LCBCodeExecution_dataset = dict(
|
||||
type=LCBCodeExecutionDataset,
|
||||
abbr='lcb_code_execution',
|
||||
path='opencompass/execution-v2',
|
||||
reader_cfg=lcb_code_execution_reader_cfg,
|
||||
infer_cfg=lcb_code_execution_infer_cfg,
|
||||
eval_cfg=lcb_code_execution_eval_cfg,
|
||||
)
|
||||
|
||||
# TestOuputput Dataset
|
||||
lcb_test_output_reader_cfg = dict(
|
||||
input_columns=[
|
||||
'prompt',
|
||||
],
|
||||
output_column='evaluation_sample',
|
||||
)
|
||||
|
||||
system_prompt = 'You are an expert Python programmer. You will be given a question (problem specification) and will generate a correct Python program that matches the specification and passes all tests. You will NOT return anything except for the program.'
|
||||
|
||||
lcb_test_output_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
# begin=[
|
||||
# dict(
|
||||
# role='SYSTEM',
|
||||
# prompt=system_prompt
|
||||
# ),
|
||||
# ],
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt='{prompt}'
|
||||
)
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=1024)
|
||||
)
|
||||
|
||||
lcb_test_output_eval_cfg = dict(
|
||||
evaluator=dict(
|
||||
type=LCBTestOutputEvaluator,
|
||||
),
|
||||
pred_role='BOT',
|
||||
)
|
||||
|
||||
LCBTestOutput_dataset = dict(
|
||||
type=LCBTestOutputPredictionDataset,
|
||||
abbr='lcb_test_output',
|
||||
path='opencompass/test_generation',
|
||||
reader_cfg=lcb_test_output_reader_cfg,
|
||||
infer_cfg=lcb_test_output_infer_cfg,
|
||||
eval_cfg=lcb_test_output_eval_cfg,
|
||||
)
|
||||
|
||||
LCB_datasets = [
|
||||
LCBCodeGeneration_dataset,
|
||||
# LCBCodeExecution_dataset,
|
||||
# LCBTestOutput_dataset,
|
||||
]
|
||||
74
opencompass/configs/datasets/livemathbench/README.md
Normal file
74
opencompass/configs/datasets/livemathbench/README.md
Normal file
@ -0,0 +1,74 @@
|
||||
# LiveMathBench
|
||||
|
||||
## Details of Datsets
|
||||
|
||||
| dataset | language | #single-choice | #multiple-choice | #fill-in-the-blank | #problem-solving |
|
||||
| -- | -- | -- | -- | -- | -- |
|
||||
| AIMC | cn | 46 | 0 | 0 | 0 |
|
||||
| AIMC | en | 46 | 0 | 0 | 0 |
|
||||
| CEE | cn | 28 | 9 | 13 | 3 |
|
||||
| CEE | en | 28 | 9 | 13 | 3 |
|
||||
| CMO | cn | 0 | 0 | 0 | 18 |
|
||||
| CMO | en | 0 | 0 | 0 | 18 |
|
||||
|
||||
|
||||
## How to use
|
||||
|
||||
|
||||
```python
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from opencompass.datasets.livemathbench import livemathbench_datasets
|
||||
|
||||
livemathbench_datasets[0].update(
|
||||
{
|
||||
'path': '/path/to/data/dir',
|
||||
'k': 'k@pass', # the max value of k in k@pass
|
||||
'n': 'number of runs', # number of runs
|
||||
}
|
||||
)
|
||||
livemathbench_datasets[0]['eval_cfg']['evaluator'].update(
|
||||
{
|
||||
'model_name': 'Qwen/Qwen2.5-72B-Instruct',
|
||||
'url': [
|
||||
'http://0.0.0.0:23333/v1',
|
||||
'...'
|
||||
] # set url of evaluation models
|
||||
}
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
> ❗️ At present, `extract_from_boxed` is used to extract answers from model responses, and one can also leverage LLM for extracting through the following parameters, but this part of the code has not been tested.
|
||||
|
||||
```python
|
||||
livemathbench_datasets[0]['eval_cfg']['evaluator'].update(
|
||||
{
|
||||
'model_name': 'Qwen/Qwen2.5-72B-Instruct',
|
||||
'url': [
|
||||
'http://0.0.0.0:23333/v1',
|
||||
'...'
|
||||
], # set url of evaluation models
|
||||
|
||||
# for LLM-based extraction
|
||||
'use_extract_model': True,
|
||||
'post_model_name': 'oc-extractor',
|
||||
'post_url': [
|
||||
'http://0.0.0.0:21006/v1,
|
||||
'...'
|
||||
]
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
## Output Samples
|
||||
|
||||
| dataset | version | metric | mode | Qwen2.5-72B-Instruct |
|
||||
|----- | ----- | ----- | ----- | -----|
|
||||
| LiveMathBench | caed8f | 1@pass | gen | 26.07 |
|
||||
| LiveMathBench | caed8f | 1@pass/std | gen | xx.xx |
|
||||
| LiveMathBench | caed8f | 2@pass | gen | xx.xx |
|
||||
| LiveMathBench | caed8f | 2@pass/std | gen | xx.xx |
|
||||
| LiveMathBench | caed8f | pass-rate | gen | xx.xx |
|
||||
|
||||
@ -0,0 +1,4 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .livemathbench_gen_caed8f import livemathbench_datasets # noqa: F401, F403
|
||||
@ -0,0 +1,49 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
|
||||
from opencompass.datasets.livemathbench import LiveMathBenchDataset, LiveMathBenchEvaluator
|
||||
|
||||
|
||||
livemathbench_reader_cfg = dict(
|
||||
input_columns=['prompt'],
|
||||
output_column='answer'
|
||||
)
|
||||
|
||||
livemathbench_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(role='HUMAN', prompt='{prompt}'),
|
||||
]
|
||||
)
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(
|
||||
type=GenInferencer,
|
||||
max_out_len=2048,
|
||||
temperature=1.0
|
||||
)
|
||||
)
|
||||
|
||||
livemathbench_eval_cfg = dict(
|
||||
evaluator=dict(
|
||||
type=LiveMathBenchEvaluator,
|
||||
model_name='Qwen/Qwen2.5-72B-Instruct',
|
||||
url=[]
|
||||
)
|
||||
)
|
||||
|
||||
livemathbench_datasets = [
|
||||
dict(
|
||||
type=LiveMathBenchDataset,
|
||||
abbr='LiveMathBench',
|
||||
path='',
|
||||
k=32,
|
||||
n=5,
|
||||
reader_cfg=livemathbench_reader_cfg,
|
||||
infer_cfg=livemathbench_infer_cfg,
|
||||
eval_cfg=livemathbench_eval_cfg
|
||||
)
|
||||
]
|
||||
@ -0,0 +1,51 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets import MATHDataset, GaoKaoMATHEvaluator
|
||||
|
||||
# ----------------------------- Model Eval Parameters -----------------------------
|
||||
|
||||
naive_model_name = 'dlc_model' # replace with your model name
|
||||
naive_model_url = ['http://0.0.0.0:23333/v1'] # Multi-apis for accerlation
|
||||
|
||||
# ----------------------------- Detailed Config -----------------------------
|
||||
|
||||
math_reader_cfg = dict(input_columns=['problem'], output_column='solution')
|
||||
|
||||
math_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(role='HUMAN', prompt='{problem}\nPlease reason step by step, and put your final answer within \\boxed{}.'),
|
||||
]
|
||||
),
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=2048),
|
||||
)
|
||||
|
||||
evaluator = dict(
|
||||
type=GaoKaoMATHEvaluator,
|
||||
model_name=naive_model_name,
|
||||
url=naive_model_url,
|
||||
language='en',
|
||||
with_postprocess=True,
|
||||
post_url=naive_model_url,
|
||||
post_model_name=naive_model_name,
|
||||
)
|
||||
|
||||
math_eval_cfg = dict(
|
||||
evaluator=evaluator,
|
||||
)
|
||||
|
||||
math_datasets = [
|
||||
dict(
|
||||
type=MATHDataset,
|
||||
abbr='math',
|
||||
path='opencompass/math',
|
||||
reader_cfg=math_reader_cfg,
|
||||
infer_cfg=math_infer_cfg,
|
||||
eval_cfg=math_eval_cfg,
|
||||
)
|
||||
]
|
||||
@ -0,0 +1,36 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets import MATHDataset, MATHEvaluator, math_postprocess_v2, normalize_final_answer
|
||||
|
||||
math_reader_cfg = dict(input_columns=['problem'], output_column='solution')
|
||||
|
||||
math_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(role='HUMAN', prompt='{problem}\nRemember to put your final answer within \\boxed{}.'),
|
||||
]
|
||||
),
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=1024),
|
||||
)
|
||||
|
||||
# postprocess v2
|
||||
math_eval_cfg = dict(
|
||||
evaluator=dict(type=MATHEvaluator, version='v2'), pred_postprocessor=dict(type=math_postprocess_v2),
|
||||
)
|
||||
|
||||
math_datasets = [
|
||||
dict(
|
||||
type=MATHDataset,
|
||||
abbr='math_prm800k_500',
|
||||
path='opencompass/math',
|
||||
file_name = 'test_prm800k_500.json',
|
||||
reader_cfg=math_reader_cfg,
|
||||
infer_cfg=math_infer_cfg,
|
||||
eval_cfg=math_eval_cfg,
|
||||
)
|
||||
]
|
||||
@ -0,0 +1,85 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets import MATHDataset, MATHEvaluator, math_postprocess_v2, normalize_final_answer
|
||||
from opencompass.datasets import MATHDataset, MATHEvaluator, math_postprocess_v2, GaoKaoMATHEvaluator
|
||||
# from opencompass.utils.model_postprocessors import naive_model_postprocess, xfinder_postprocess
|
||||
from opencompass.utils.postprocessors.naive import MATH_NAVIE_PROMPT_TEMPLATE
|
||||
|
||||
# ----------------------------- Eval Parameters -----------------------------
|
||||
## Postprocess function
|
||||
post_func = 're' # 're', 'xfinder_model', 'naive_model'
|
||||
|
||||
## Evalute function
|
||||
eval_func = 'naive_model' # 're', 'naive_model'
|
||||
|
||||
|
||||
## Model api url
|
||||
# xfinder_url = 'http://0.0.0.0:23333/v1' # for 'xFinder-qwen1505' if post_func is 'xfinder_model'
|
||||
# naive_model_name = 'Qwen/Qwen2.5-72B-Instruct' # replace with your model name
|
||||
naive_model_name = 'dlc_model'
|
||||
# naive_model_url = [
|
||||
# 'http://172.30.56.38:23001/v1',
|
||||
# ] # Multi-apis for accerlation
|
||||
naive_model_url = [
|
||||
"http://172.30.56.38:23001/v1",
|
||||
"http://172.30.8.4:23003/v1",
|
||||
"http://172.30.8.14:23002/v1",
|
||||
"http://172.30.48.80:23004/v1",
|
||||
"http://172.30.56.132:23005/v1",
|
||||
"http://172.30.16.115:23006/v1",
|
||||
"http://172.30.48.82:23007/v1",
|
||||
"http://172.30.24.53:23008/v1",
|
||||
"http://172.30.56.141:23009/v1",
|
||||
"http://172.30.8.35:23010/v1",
|
||||
"http://172.30.48.85:23011/v1",
|
||||
"http://172.30.16.116:23012/v1"
|
||||
]
|
||||
# ----------------------------- Detailed Config -----------------------------
|
||||
|
||||
math_reader_cfg = dict(input_columns=['problem'], output_column='solution')
|
||||
|
||||
math_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
dict(role='HUMAN', prompt='{problem}\nRemember to put your final answer within \\boxed{}.'),
|
||||
]
|
||||
),
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=8192),
|
||||
)
|
||||
|
||||
|
||||
if post_func == 're':
|
||||
pred_postprocessor = dict(type=math_postprocess_v2)
|
||||
|
||||
|
||||
if eval_func == 're':
|
||||
evaluator = dict(type=MATHEvaluator, version='v2')
|
||||
elif eval_func == 'naive_model':
|
||||
evaluator = dict(
|
||||
type=GaoKaoMATHEvaluator,
|
||||
judge_model_name=naive_model_name,
|
||||
url=naive_model_url,
|
||||
)
|
||||
|
||||
# postprocess v2
|
||||
math_eval_cfg = dict(
|
||||
evaluator=evaluator,
|
||||
pred_postprocessor=pred_postprocessor,
|
||||
)
|
||||
|
||||
math_datasets = [
|
||||
dict(
|
||||
type=MATHDataset,
|
||||
abbr='math_prm800k_500-llmjudge',
|
||||
path='opencompass/math',
|
||||
file_name = 'test_prm800k_500.json',
|
||||
reader_cfg=math_reader_cfg,
|
||||
infer_cfg=math_infer_cfg,
|
||||
eval_cfg=math_eval_cfg,
|
||||
)
|
||||
]
|
||||
@ -0,0 +1,40 @@
|
||||
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||
from opencompass.datasets import SanitizedMBPPDataset, MBPPEvaluator
|
||||
|
||||
sanitized_mbpp_reader_cfg = dict(input_columns=['text', 'test_list'], output_column='test_list_2')
|
||||
|
||||
sanitized_mbpp_infer_cfg = dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
round=[
|
||||
# dict(role='HUMAN', prompt='You are an expert Python programmer, and here is your task:\nWrite a function to find the similar elements from the given two tuple lists.\nYour code should pass these tests:\n\nassert similar_elements((3, 4, 5, 6),(5, 7, 4, 10)) == (4, 5)\nassert similar_elements((1, 2, 3, 4),(5, 4, 3, 7)) == (3, 4)\nassert similar_elements((11, 12, 14, 13),(17, 15, 14, 13)) == (13, 14)\n',),
|
||||
# dict(role='BOT', prompt='```python\ndef similar_elements(test_tup1, test_tup2):\n res = tuple(set(test_tup1) & set(test_tup2))\n return (res)```',),
|
||||
|
||||
# dict(role='HUMAN', prompt='You are an expert Python programmer, and here is your task:\nWrite a python function to identify non-prime numbers.\nYour code should pass these tests:\n\nassert is_not_prime(2) == False\nassert is_not_prime(10) == True\nassert is_not_prime(35) == True\n',),
|
||||
# dict(role='BOT', prompt='```python\nimport math\ndef is_not_prime(n):\n result = False\n for i in range(2,int(math.sqrt(n)) + 1):\n if n %% i == 0:\n result = True\n return result```',),
|
||||
|
||||
# dict(role='HUMAN', prompt='You are an expert Python programmer, and here is your task:\nWrite a function to find the largest integers from a given list of numbers using heap queue algorithm.\nYour code should pass these tests:\n\nassert heap_queue_largest( [25, 35, 22, 85, 14, 65, 75, 22, 58],3)==[85, 75, 65]\nassert heap_queue_largest( [25, 35, 22, 85, 14, 65, 75, 22, 58],2)==[85, 75]\nassert heap_queue_largest( [25, 35, 22, 85, 14, 65, 75, 22, 58],5)==[85, 75, 65, 58, 35]\n',),
|
||||
# dict(role='BOT', prompt='```python\nimport heapq as hq\ndef heap_queue_largest(nums,n):\n largest_nums = hq.nlargest(n, nums)\n return largest_nums```',),
|
||||
dict(role='HUMAN', prompt='You are an expert Python programmer, and here is your task:\n{text}\nYour code should pass these tests:\n\n{test_list}\n You should submit your final solution in the following format: ```python\n\n```',),
|
||||
],
|
||||
),
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=512),
|
||||
)
|
||||
|
||||
sanitized_mbpp_eval_cfg = dict(evaluator=dict(type=MBPPEvaluator), pred_role='BOT')
|
||||
|
||||
sanitized_mbpp_datasets = [
|
||||
dict(
|
||||
type=SanitizedMBPPDataset,
|
||||
abbr='sanitized_mbpp',
|
||||
path='opencompass/sanitized_mbpp',
|
||||
reader_cfg=sanitized_mbpp_reader_cfg,
|
||||
infer_cfg=sanitized_mbpp_infer_cfg,
|
||||
eval_cfg=sanitized_mbpp_eval_cfg,
|
||||
)
|
||||
]
|
||||
135
opencompass/configs/datasets/musr/musr_gen_3622bb.py
Normal file
135
opencompass/configs/datasets/musr/musr_gen_3622bb.py
Normal file
@ -0,0 +1,135 @@
|
||||
from opencompass.datasets import MusrDataset, MusrEvaluator
|
||||
from opencompass.openicl import PromptTemplate, ZeroRetriever, GenInferencer
|
||||
|
||||
|
||||
DATASET_CONFIGS = {
|
||||
'murder_mysteries': {
|
||||
'abbr': 'musr_murder_mysteries',
|
||||
'name': 'murder_mysteries',
|
||||
'path': 'opencompass/musr',
|
||||
'reader_cfg': dict(
|
||||
input_columns=['context', 'question_text', 'question', 'answer', 'choices', 'choices_str', 'intermediate_trees', 'intermediate_data', 'prompt', 'system_prompt', 'gold_answer', 'scidx', 'self_consistency_n', 'ablation_name'],
|
||||
output_column='gold_answer',
|
||||
),
|
||||
'infer_cfg': dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
begin=[
|
||||
dict(
|
||||
role='SYSTEM',
|
||||
fallback_role='HUMAN',
|
||||
prompt='{system_prompt}'
|
||||
)
|
||||
],
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt='{prompt}'
|
||||
),
|
||||
]
|
||||
),
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=2048),
|
||||
),
|
||||
'eval_cfg': dict(
|
||||
evaluator=dict(
|
||||
type=MusrEvaluator,
|
||||
answer_index_modifier=1,
|
||||
self_consistency_n=1
|
||||
),
|
||||
),
|
||||
},
|
||||
'object_placements': {
|
||||
'abbr': 'musr_object_placements',
|
||||
'name': 'object_placements',
|
||||
'path': 'opencompass/musr',
|
||||
'reader_cfg': dict(
|
||||
input_columns=['context', 'question_text', 'question', 'answer', 'choices', 'choices_str', 'intermediate_trees', 'intermediate_data', 'prompt', 'system_prompt', 'gold_answer', 'scidx', 'self_consistency_n', 'ablation_name'],
|
||||
output_column='gold_answer',
|
||||
),
|
||||
'infer_cfg': dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
begin=[
|
||||
dict(
|
||||
role='SYSTEM',
|
||||
fallback_role='HUMAN',
|
||||
prompt='{system_prompt}'
|
||||
)
|
||||
],
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt='{prompt}'
|
||||
),
|
||||
]
|
||||
),
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=512),
|
||||
),
|
||||
'eval_cfg': dict(
|
||||
evaluator=dict(
|
||||
type=MusrEvaluator,
|
||||
answer_index_modifier=1,
|
||||
self_consistency_n=1
|
||||
),
|
||||
),
|
||||
},
|
||||
'team_allocation': {
|
||||
'abbr': 'musr_team_allocation',
|
||||
'name': 'team_allocation',
|
||||
'path': 'opencompass/musr',
|
||||
'reader_cfg': dict(
|
||||
input_columns=['context', 'question_text', 'question', 'answer', 'choices', 'choices_str', 'intermediate_trees', 'intermediate_data', 'prompt', 'system_prompt', 'gold_answer', 'scidx', 'self_consistency_n', 'ablation_name'],
|
||||
output_column='gold_answer',
|
||||
),
|
||||
'infer_cfg': dict(
|
||||
prompt_template=dict(
|
||||
type=PromptTemplate,
|
||||
template=dict(
|
||||
begin=[
|
||||
dict(
|
||||
role='SYSTEM',
|
||||
fallback_role='HUMAN',
|
||||
prompt='{system_prompt}'
|
||||
)
|
||||
],
|
||||
round=[
|
||||
dict(
|
||||
role='HUMAN',
|
||||
prompt='{prompt}'
|
||||
),
|
||||
]
|
||||
),
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_out_len=512),
|
||||
),
|
||||
'eval_cfg': dict(
|
||||
evaluator=dict(
|
||||
type=MusrEvaluator,
|
||||
answer_index_modifier=1,
|
||||
self_consistency_n=1
|
||||
),
|
||||
),
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
musr_datasets = []
|
||||
|
||||
for config in DATASET_CONFIGS.values():
|
||||
dataset = dict(
|
||||
abbr=config['abbr'],
|
||||
type=MusrDataset,
|
||||
path=config['path'],
|
||||
name=config['name'],
|
||||
reader_cfg=config['reader_cfg'],
|
||||
infer_cfg=config['infer_cfg'],
|
||||
eval_cfg=config['eval_cfg'],
|
||||
)
|
||||
musr_datasets.append(dataset)
|
||||
28
opencompass/configs/datasets/ruler/ruler_64k_gen.py
Normal file
28
opencompass/configs/datasets/ruler/ruler_64k_gen.py
Normal file
@ -0,0 +1,28 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .ruler_cwe_gen import cwe_datasets as cwe # CWE
|
||||
from .ruler_fwe_gen import fwe_datasets as fwe # FWE
|
||||
from .ruler_niah_gen import niah_datasets as niah # Niah
|
||||
from .ruler_qa_gen import qa_datasets as qa # QA
|
||||
from .ruler_vt_gen import vt_datasets as vt # VT
|
||||
|
||||
|
||||
import_ds = sum((cwe, fwe, niah, qa, vt), [])
|
||||
|
||||
# Evaluation config
|
||||
NUM_SAMPLES = 100 # Change to the number of samples you need
|
||||
# Change the context lengths to be tested
|
||||
max_seq_lens = [1024 * 64]
|
||||
abbr_suffixs: list[str] = ['64k']
|
||||
|
||||
ruler_datasets = []
|
||||
|
||||
# Different seq length
|
||||
for max_seq_len, abbr_suffix in zip(max_seq_lens, abbr_suffixs):
|
||||
for dataset in import_ds:
|
||||
tmp_dataset = dataset.deepcopy()
|
||||
tmp_dataset['abbr'] = tmp_dataset['abbr'] + '_' + abbr_suffix
|
||||
tmp_dataset['num_samples'] = NUM_SAMPLES
|
||||
tmp_dataset['max_seq_length'] = max_seq_len
|
||||
ruler_datasets.append(tmp_dataset)
|
||||
@ -6,6 +6,7 @@ with read_base():
|
||||
from .ruler_8k_gen import ruler_datasets as ruler_8k_ds
|
||||
from .ruler_16k_gen import ruler_datasets as ruler_16k_ds
|
||||
from .ruler_32k_gen import ruler_datasets as ruler_32k_ds
|
||||
from .ruler_64k_gen import ruler_datasets as ruler_64k_ds
|
||||
from .ruler_128k_gen import ruler_datasets as ruler_128k_ds
|
||||
|
||||
ruler_combined_datasets = sum((v for k, v in locals().items() if k.endswith('_ds')), [])
|
||||
|
||||
@ -118,7 +118,7 @@ for _name, _prompt in sub_map.items():
|
||||
]),
|
||||
),
|
||||
retriever=dict(type=ZeroRetriever),
|
||||
inferencer=dict(type=GenInferencer, max_seq_len=4096, max_out_len=2048),
|
||||
inferencer=dict(type=GenInferencer, max_seq_len=4096, max_out_len=4096),
|
||||
)
|
||||
|
||||
subjective_eval_cfg = dict(
|
||||
|
||||
@ -47,8 +47,3 @@ for _name in subjective_all_sets:
|
||||
infer_cfg=subjective_infer_cfg,
|
||||
eval_cfg=subjective_eval_cfg,
|
||||
))
|
||||
# ds1000_eval_cfg = dict(
|
||||
# evaluator=dict(type=DS1000Evaluator),
|
||||
# pred_role='BOT',
|
||||
# pred_postprocessor=dict(type=ds1000_postprocess),
|
||||
# )
|
||||
|
||||
@ -10,21 +10,19 @@ api_meta_template = dict(
|
||||
|
||||
models = [
|
||||
dict(
|
||||
path='Bailing-Lite-0830',
|
||||
path='Bailing-Lite-1116',
|
||||
token='', # set your key here or in environment variable BAILING_API_KEY
|
||||
url='https://bailingchat.alipay.com/chat/completions',
|
||||
type=BailingAPI,
|
||||
meta_template=api_meta_template,
|
||||
query_per_second=1,
|
||||
max_seq_len=4096,
|
||||
max_out_len=11264,
|
||||
batch_size=1,
|
||||
generation_kwargs={
|
||||
'temperature': 0.4,
|
||||
'temperature': 0.01,
|
||||
'top_p': 1.0,
|
||||
'top_k': -1,
|
||||
'n': 1,
|
||||
'logprobs': 1,
|
||||
'use_beam_search': False,
|
||||
},
|
||||
),
|
||||
]
|
||||
@ -10,21 +10,19 @@ api_meta_template = dict(
|
||||
|
||||
models = [
|
||||
dict(
|
||||
path='Bailing-Lite-0830',
|
||||
path='Bailing-Pro-1120',
|
||||
token='', # set your key here or in environment variable BAILING_API_KEY
|
||||
url='https://bailingchat.alipay.com/chat/completions',
|
||||
type=BailingAPI,
|
||||
meta_template=api_meta_template,
|
||||
query_per_second=1,
|
||||
max_seq_len=4096,
|
||||
max_out_len=11264,
|
||||
batch_size=1,
|
||||
generation_kwargs={
|
||||
'temperature': 0.4,
|
||||
'temperature': 0.01,
|
||||
'top_p': 1.0,
|
||||
'top_k': -1,
|
||||
'n': 1,
|
||||
'logprobs': 1,
|
||||
'use_beam_search': False,
|
||||
},
|
||||
),
|
||||
]
|
||||
@ -0,0 +1,20 @@
|
||||
from opencompass.models import TurboMindModelwithChatTemplate
|
||||
|
||||
models = [
|
||||
dict(
|
||||
type=TurboMindModelwithChatTemplate,
|
||||
abbr='deepseek-v2_lite-chat-turbomind',
|
||||
path='deepseek-ai/DeepSeek-V2-Lite-Chat',
|
||||
engine_config=dict(
|
||||
session_len=7168,
|
||||
max_batch_size=4,
|
||||
tp=2,
|
||||
cache_max_entry_count=0.7,
|
||||
),
|
||||
gen_config=dict(top_k=1, temperature=1e-6, top_p=0.9),
|
||||
max_seq_len=7168,
|
||||
max_out_len=2048,
|
||||
batch_size=4,
|
||||
run_cfg=dict(num_gpus=2),
|
||||
)
|
||||
]
|
||||
17
opencompass/configs/models/gemma/lmdeploy_gemma_27b.py
Normal file
17
opencompass/configs/models/gemma/lmdeploy_gemma_27b.py
Normal file
@ -0,0 +1,17 @@
|
||||
from opencompass.models import TurboMindModel
|
||||
|
||||
models = [
|
||||
dict(
|
||||
type=TurboMindModel,
|
||||
abbr='gemma-2-27b-turbomind',
|
||||
path='google/gemma-2-27b',
|
||||
engine_config=dict(session_len=16384, max_batch_size=16, tp=2),
|
||||
gen_config=dict(
|
||||
top_k=1, temperature=1e-6, top_p=0.9, max_new_tokens=4096
|
||||
),
|
||||
max_seq_len=16384,
|
||||
max_out_len=4096,
|
||||
batch_size=16,
|
||||
run_cfg=dict(num_gpus=2),
|
||||
)
|
||||
]
|
||||
17
opencompass/configs/models/gemma/lmdeploy_gemma_9b.py
Normal file
17
opencompass/configs/models/gemma/lmdeploy_gemma_9b.py
Normal file
@ -0,0 +1,17 @@
|
||||
from opencompass.models import TurboMindModel
|
||||
|
||||
models = [
|
||||
dict(
|
||||
type=TurboMindModel,
|
||||
abbr='gemma-2-9b-turbomind',
|
||||
path='google/gemma-2-9b',
|
||||
engine_config=dict(session_len=16384, max_batch_size=16, tp=1),
|
||||
gen_config=dict(
|
||||
top_k=1, temperature=1e-6, top_p=0.9, max_new_tokens=4096
|
||||
),
|
||||
max_seq_len=16384,
|
||||
max_out_len=4096,
|
||||
batch_size=16,
|
||||
run_cfg=dict(num_gpus=1),
|
||||
)
|
||||
]
|
||||
@ -0,0 +1,22 @@
|
||||
from opencompass.models import TurboMindModelwithChatTemplate
|
||||
|
||||
models = [
|
||||
dict(
|
||||
type=TurboMindModelwithChatTemplate,
|
||||
abbr='mixtral-large-instruct-2411-turbomind',
|
||||
path='mistralai/Mistral-Large-Instruct-2411',
|
||||
engine_config=dict(
|
||||
session_len=32768,
|
||||
max_batch_size=16,
|
||||
tp=4,
|
||||
cache_max_entry_count=0.7,
|
||||
),
|
||||
gen_config=dict(
|
||||
top_k=1, temperature=1e-6, top_p=0.9, max_new_tokens=4096
|
||||
),
|
||||
max_seq_len=32768,
|
||||
max_out_len=4096,
|
||||
batch_size=8,
|
||||
run_cfg=dict(num_gpus=4),
|
||||
)
|
||||
]
|
||||
22
opencompass/configs/summarizers/PMMEval.py
Normal file
22
opencompass/configs/summarizers/PMMEval.py
Normal file
@ -0,0 +1,22 @@
|
||||
from mmengine.config import read_base
|
||||
|
||||
with read_base():
|
||||
from .groups.PMMEval import PMMEval_summary_groups
|
||||
|
||||
|
||||
summarizer = dict(
|
||||
dataset_abbrs=[
|
||||
'flores',
|
||||
'humanevalxl',
|
||||
'mgsm',
|
||||
'mhellaswag',
|
||||
'mifeval',
|
||||
'mlogiqa',
|
||||
'mmmlu',
|
||||
'xnli'
|
||||
],
|
||||
summary_groups=sum(
|
||||
[v for k, v in locals().items() if k.endswith('_summary_groups')], []
|
||||
),
|
||||
)
|
||||
|
||||
41
opencompass/configs/summarizers/groups/PMMEval.py
Normal file
41
opencompass/configs/summarizers/groups/PMMEval.py
Normal file
@ -0,0 +1,41 @@
|
||||
NATURAL_LANGUAGE_FULLNAMES = ['English', 'Chinese', 'Arabic', 'Spanish', 'French', 'Japanese', 'Korean', 'Portuguese', 'Thai', 'Vietnamese']
|
||||
NATURAL_LANGUAGE_FULLNAMES_FLORES = ['Chinese', 'Arabic', 'Spanish', 'French', 'Japanese', 'Korean', 'Portuguese', 'Thai', 'Vietnamese']
|
||||
NATURAL_LANGUAGE_CODES = ['en', 'zh', 'ar', 'es', 'fr', 'ja', 'ko', 'pt', 'th', 'vi']
|
||||
NATURAL_LANGUAGE_CODES_MMMLU = ['EN-US', 'ZH-CN', 'AR-XY', 'ES-LA', 'FR-FR', 'JA-JP', 'KO-KR', 'PT-BR', 'TH-TL', 'VI-VT']
|
||||
|
||||
PMMEval_summary_groups = [
|
||||
{
|
||||
'name': 'flores',
|
||||
'subsets': [f'flores-{lang_fullname}' for lang_fullname in NATURAL_LANGUAGE_FULLNAMES_FLORES]
|
||||
},
|
||||
{
|
||||
'name': 'humanevalxl',
|
||||
'subsets': [f'humanevalxl-python-{lang_fullname}' for lang_fullname in NATURAL_LANGUAGE_FULLNAMES] + \
|
||||
[f'humanevalxl-java-{lang_fullname}' for lang_fullname in NATURAL_LANGUAGE_FULLNAMES] + \
|
||||
[f'humanevalxl-javascript-{lang_fullname}' for lang_fullname in NATURAL_LANGUAGE_FULLNAMES]
|
||||
},
|
||||
{
|
||||
'name': 'mgsm',
|
||||
'subsets': [f'mgsm-{lang_code}' for lang_code in NATURAL_LANGUAGE_CODES]
|
||||
},
|
||||
{
|
||||
'name': 'mhellaswag',
|
||||
'subsets': [f'mhellaswag-{lang_code}' for lang_code in NATURAL_LANGUAGE_CODES]
|
||||
},
|
||||
{
|
||||
'name': 'mifeval',
|
||||
'subsets': [f'mifeval-{lang_code}' for lang_code in NATURAL_LANGUAGE_CODES]
|
||||
},
|
||||
{
|
||||
'name': 'mlogiqa',
|
||||
'subsets': [f'mlogiqa-{lang_code}' for lang_code in NATURAL_LANGUAGE_CODES]
|
||||
},
|
||||
{
|
||||
'name': 'mmmlu',
|
||||
'subsets': [f'mmmlu-{lang_code}' for lang_code in NATURAL_LANGUAGE_CODES_MMMLU]
|
||||
},
|
||||
{
|
||||
'name': 'xnli',
|
||||
'subsets': [f'xnli-{lang_code}' for lang_code in NATURAL_LANGUAGE_CODES]
|
||||
}
|
||||
]
|
||||
5
opencompass/configs/summarizers/groups/korbench.py
Normal file
5
opencompass/configs/summarizers/groups/korbench.py
Normal file
@ -0,0 +1,5 @@
|
||||
korbench_summary_groups = []
|
||||
categories = ['cipher', 'counterfactual', 'logic', 'operation', 'puzzle']
|
||||
mixed_categories = ['Multi-Q', 'Multi-R', 'Multi-RQ']
|
||||
korbench_summary_groups.append({'name': 'korbench_single', 'subsets': [f'korbench_{c}' for c in categories]})
|
||||
korbench_summary_groups.append({'name': 'korbench_mixed', 'subsets': [f'korbench_{c}' for c in mixed_categories]})
|
||||
@ -13,7 +13,7 @@ default_ruler_tasks = [
|
||||
'ruler_qa_squad',
|
||||
'ruler_qa_hotpotqa',
|
||||
]
|
||||
context_window_sizes = ['4k', '8k', '16k', '32k', '128k', '1m']
|
||||
context_window_sizes = ['4k', '8k', '16k', '32k', '64k', '128k', '1m']
|
||||
|
||||
ruler_summary_groups = []
|
||||
for context_window_size in context_window_sizes:
|
||||
|
||||
@ -35,7 +35,12 @@ ruler_32k_summarizer = dict(
|
||||
[v for k, v in locals().items() if k.endswith('_summary_groups')], []
|
||||
),
|
||||
)
|
||||
|
||||
ruler_64k_summarizer = dict(
|
||||
dataset_abbrs=['ruler_64k'],
|
||||
summary_groups=sum(
|
||||
[v for k, v in locals().items() if k.endswith('_summary_groups')], []
|
||||
),
|
||||
)
|
||||
ruler_128k_summarizer = dict(
|
||||
dataset_abbrs=['ruler_128k'],
|
||||
summary_groups=sum(
|
||||
@ -56,6 +61,7 @@ ruler_combined_summarizer = dict(
|
||||
'ruler_8k',
|
||||
'ruler_16k',
|
||||
'ruler_32k',
|
||||
'ruler_64k',
|
||||
'ruler_128k',
|
||||
'ruler_1m',
|
||||
],
|
||||
|
||||
7
opencompass/configs/summarizers/simpleqa.py
Normal file
7
opencompass/configs/summarizers/simpleqa.py
Normal file
@ -0,0 +1,7 @@
|
||||
summarizer = dict(
|
||||
dataset_abbrs=[
|
||||
['simpleqa', 'accuracy_given_attempted'],
|
||||
['simpleqa', 'f1'],
|
||||
],
|
||||
summary_groups=sum([v for k, v in locals().items() if k.endswith('_summary_groups')], []),
|
||||
)
|
||||
8
opencompass/datasets/PMMEval/__init__.py
Executable file
8
opencompass/datasets/PMMEval/__init__.py
Executable file
@ -0,0 +1,8 @@
|
||||
from .flores import * # noqa: F401, F403
|
||||
from .humanevalxl import * # noqa: F401, F403
|
||||
from .mgsm import * # noqa: F401, F403
|
||||
from .mhellaswag import * # noqa: F401, F403
|
||||
from .mifeval import * # noqa: F401, F403
|
||||
from .mlogiqa import * # noqa: F401, F403
|
||||
from .mmmlu import * # noqa: F401, F403
|
||||
from .xnli import * # noqa: F401, F403
|
||||
162
opencompass/datasets/PMMEval/flores.py
Executable file
162
opencompass/datasets/PMMEval/flores.py
Executable file
@ -0,0 +1,162 @@
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
from typing import Tuple
|
||||
|
||||
import numpy as np
|
||||
from datasets import Dataset
|
||||
from sacrebleu.metrics import BLEU
|
||||
from sacrebleu.tokenizers.tokenizer_13a import Tokenizer13a
|
||||
from sacrebleu.tokenizers.tokenizer_zh import TokenizerZh
|
||||
|
||||
from opencompass.datasets.base import BaseDataset
|
||||
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
||||
from opencompass.registry import LOAD_DATASET, TEXT_POSTPROCESSORS
|
||||
from opencompass.utils import get_data_path
|
||||
|
||||
|
||||
def wmt_postprocess(text: str, lang: str) -> str:
|
||||
text = text.strip()
|
||||
texts = list(x.strip() for x in text.split('\n'))
|
||||
texts = list(x for x in texts if x != '')
|
||||
text = '\n'.join(texts)
|
||||
text = tokenize(text, lang)
|
||||
return text
|
||||
|
||||
|
||||
def compute_maximum_bleu_value(gen: str, ref: str, lang: str):
|
||||
gens = list(x.strip() for x in gen.split('\n'))
|
||||
gens = list(x for x in gens if x != '')
|
||||
|
||||
gens_tokens = list(wmt_postprocess(x, lang) for x in gens)
|
||||
ref_tokens = wmt_postprocess(ref, lang)
|
||||
|
||||
scorer = BLEU(tokenize='13a', effective_order=True)
|
||||
|
||||
maximum_bleu_value = -100.0
|
||||
maximum_bleu_object = None
|
||||
|
||||
for i in range(0, len(gens_tokens)):
|
||||
for j in range(i, len(gens_tokens)):
|
||||
gens_tokens_region = ' '.join(gens_tokens[i:j + 1])
|
||||
sentence_bleu = scorer.sentence_score(gens_tokens_region,
|
||||
[ref_tokens])
|
||||
|
||||
if sentence_bleu.score > maximum_bleu_value:
|
||||
maximum_bleu_value = sentence_bleu.score
|
||||
maximum_bleu_object = sentence_bleu
|
||||
|
||||
if maximum_bleu_object is None:
|
||||
sentence_bleu = scorer.sentence_score('', [ref_tokens])
|
||||
return sentence_bleu
|
||||
else:
|
||||
return maximum_bleu_object
|
||||
|
||||
|
||||
def trim_multiple_space(tokes):
|
||||
return ''.join(tokes).strip().split()
|
||||
|
||||
|
||||
class SpaceTokenizer(object):
|
||||
|
||||
def __call__(self, sent):
|
||||
if type(sent) == list:
|
||||
print(sent)
|
||||
raise ValueError()
|
||||
return ' '.join(sent.strip().split())
|
||||
|
||||
|
||||
class NonASCIITokenizer(object):
|
||||
|
||||
def __init__(self):
|
||||
self.is_cjk = re.compile('([\u2e80-\u9fff]|' # 中日韩
|
||||
'[\ua960-\ua97f]|' # 谚文字母扩展A
|
||||
'[\uac00-\ud7ff]|' # 谚文音节+谚文字母扩展B
|
||||
'[\u0E00-\u0E7F]' # 泰文
|
||||
')')
|
||||
|
||||
def __call__(self, sent):
|
||||
sent = sent.strip()
|
||||
chs = list(sent)
|
||||
line_chtok = []
|
||||
for ch in chs:
|
||||
if self.is_cjk.match(ch):
|
||||
line_chtok.append(' ')
|
||||
line_chtok.append(ch)
|
||||
line_chtok.append(' ')
|
||||
else:
|
||||
line_chtok.append(ch)
|
||||
line_chtok = trim_multiple_space(line_chtok)
|
||||
return ' '.join(line_chtok)
|
||||
|
||||
|
||||
def build_tokenizer(lang: str):
|
||||
if lang == 'Chinese':
|
||||
return TokenizerZh()
|
||||
elif lang in {'Japanese', 'Korean', 'Thai'}:
|
||||
return NonASCIITokenizer()
|
||||
else:
|
||||
return SpaceTokenizer()
|
||||
|
||||
|
||||
def tokenize(sent, lang):
|
||||
tokenizer = build_tokenizer(lang)
|
||||
final_tokenizer = Tokenizer13a()
|
||||
return final_tokenizer(tokenizer(sent))
|
||||
|
||||
|
||||
@TEXT_POSTPROCESSORS.register_module('pmmeval_flores')
|
||||
def pmmeval_flores_postprocess(text: str, lang_fullname: str) -> Tuple[str]:
|
||||
return text, lang_fullname
|
||||
|
||||
|
||||
@LOAD_DATASET.register_module()
|
||||
class PMMEvalFloresDataset(BaseDataset):
|
||||
|
||||
@staticmethod
|
||||
def load(path: str, lang_fullname: str):
|
||||
data_path = get_data_path(path)
|
||||
|
||||
if os.environ.get('DATASET_SOURCE') == 'ModelScope':
|
||||
from modelscope import MsDataset
|
||||
dataset = MsDataset.load(dataset_name=data_path,
|
||||
subset_name='flores',
|
||||
split=f'test/{lang_fullname}')
|
||||
else:
|
||||
dataset = list()
|
||||
filename = os.path.join(data_path,
|
||||
f'flores/test/{lang_fullname}.jsonl')
|
||||
with open(filename, mode='r', encoding='utf-8') as f:
|
||||
for line in f:
|
||||
line = json.loads(line.strip())
|
||||
dataset.append(line)
|
||||
dataset = Dataset.from_list(dataset)
|
||||
|
||||
return dataset
|
||||
|
||||
|
||||
class PMMEvalFloresEvaluator(BaseEvaluator):
|
||||
|
||||
def score(self, predictions, references):
|
||||
maximum_bleu_results = list()
|
||||
for (pred, tgt_lang), ref in zip(predictions, references):
|
||||
maximum_bleu_results.append(
|
||||
compute_maximum_bleu_value(pred, ref, tgt_lang))
|
||||
|
||||
maximum_corpus_bleu_counts = sum(
|
||||
np.array(x.counts) for x in maximum_bleu_results).tolist()
|
||||
maximum_corpus_bleu_totals = sum(
|
||||
np.array(x.totals) for x in maximum_bleu_results).tolist()
|
||||
maximum_corpus_bleu_sys_len = sum(x.sys_len
|
||||
for x in maximum_bleu_results)
|
||||
maximum_corpus_bleu_ref_len = sum(x.ref_len
|
||||
for x in maximum_bleu_results)
|
||||
|
||||
maximum_bleu_result = BLEU.compute_bleu(
|
||||
correct=maximum_corpus_bleu_counts,
|
||||
total=maximum_corpus_bleu_totals,
|
||||
sys_len=maximum_corpus_bleu_sys_len,
|
||||
ref_len=maximum_corpus_bleu_ref_len)
|
||||
|
||||
result = {'BLEU': round(maximum_bleu_result.score, 2)}
|
||||
return result
|
||||
226
opencompass/datasets/PMMEval/humanevalxl.py
Executable file
226
opencompass/datasets/PMMEval/humanevalxl.py
Executable file
@ -0,0 +1,226 @@
|
||||
import json
|
||||
import os
|
||||
import os.path as osp
|
||||
import re
|
||||
import subprocess
|
||||
import tempfile
|
||||
import time
|
||||
from shutil import copyfile
|
||||
|
||||
from datasets import Dataset
|
||||
|
||||
from opencompass.datasets.base import BaseDataset
|
||||
from opencompass.datasets.humaneval import humaneval_postprocess_v2
|
||||
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
||||
from opencompass.registry import LOAD_DATASET
|
||||
from opencompass.utils import get_data_path
|
||||
|
||||
_LANGUAGE_NAME_DICT = {
|
||||
'java': 'Java',
|
||||
'javascript': 'JavaScript',
|
||||
'js': 'JavaScript',
|
||||
'python': 'Python',
|
||||
}
|
||||
|
||||
|
||||
@LOAD_DATASET.register_module()
|
||||
class PMMEvalHumanEvalXLDataset(BaseDataset):
|
||||
|
||||
@staticmethod
|
||||
def load(path: str, lang: str, program_lang: str):
|
||||
data_path = get_data_path(path)
|
||||
|
||||
if os.environ.get('DATASET_SOURCE') == 'ModelScope':
|
||||
from modelscope import MsDataset
|
||||
dataset = MsDataset.load(dataset_name=data_path,
|
||||
subset_name='humaneval-xl',
|
||||
split=f'test/{program_lang}/{lang}')
|
||||
else:
|
||||
dataset = list()
|
||||
filename = os.path.join(
|
||||
data_path, f'humaneval-xl/test/{program_lang}/{lang}.jsonl')
|
||||
with open(filename, mode='r', encoding='utf-8') as f:
|
||||
for line in f:
|
||||
line = json.loads(line.strip())
|
||||
dataset.append(line)
|
||||
dataset = Dataset.from_list(dataset)
|
||||
|
||||
return dataset
|
||||
|
||||
|
||||
class PMMEvalHumanEvalXLEvaluator(BaseEvaluator):
|
||||
|
||||
def __init__(self,
|
||||
language,
|
||||
ip_address='localhost',
|
||||
text_language='',
|
||||
port='',
|
||||
retry=2,
|
||||
timeout=600) -> None:
|
||||
assert language in _LANGUAGE_NAME_DICT.keys(), (
|
||||
f'language must be in {list(_LANGUAGE_NAME_DICT.keys())}')
|
||||
if language == 'rust':
|
||||
timeout *= 10 # rust need more time
|
||||
self.language = language
|
||||
self.text_language = text_language
|
||||
self.ip_address = ip_address
|
||||
self.port = port
|
||||
self.retry = retry
|
||||
self.timeout = timeout
|
||||
super().__init__()
|
||||
|
||||
def score(self, predictions, references):
|
||||
predictions = [{
|
||||
'task_id':
|
||||
f'{_LANGUAGE_NAME_DICT[self.language]}/{i}',
|
||||
'generation':
|
||||
_clean_up_code(pred, self.language, refer),
|
||||
} for i, (pred, refer) in enumerate(zip(predictions, references))]
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
tmp_out_path = osp.join(
|
||||
tmp_dir,
|
||||
f'humanevalx_{self.language}_{self.text_language}.json')
|
||||
with open(tmp_out_path, 'w') as f:
|
||||
for pred in predictions:
|
||||
f.write(json.dumps(pred) + '\n')
|
||||
|
||||
num_retry = 0
|
||||
while num_retry < self.retry:
|
||||
succeed, output = self._code_eval_service(
|
||||
file_path=tmp_out_path)
|
||||
if not succeed and '(56) Recv failure' in output:
|
||||
# only retry when connection failed
|
||||
num_retry += 1
|
||||
# wait a min in case the service load is too high
|
||||
time.sleep(60)
|
||||
else:
|
||||
break
|
||||
|
||||
if succeed:
|
||||
if isinstance(output, str):
|
||||
return json.loads(output)
|
||||
elif isinstance(output, dict):
|
||||
return output
|
||||
|
||||
ref_url = 'https://opencompass.readthedocs.io/en/latest/advanced_guides/code_eval_service.html' # noqa
|
||||
if hasattr(self, '_out_dir'):
|
||||
result_file_path = re.sub('results', 'mid_results',
|
||||
self._out_dir) + '.json' # noqa
|
||||
if not osp.exists(osp.dirname(result_file_path)):
|
||||
os.makedirs(osp.dirname(result_file_path))
|
||||
else:
|
||||
result_file_path = os.path.join(
|
||||
'outputs', f'humanevalx_{self.language}.json')
|
||||
copyfile(tmp_out_path, result_file_path)
|
||||
raise Exception(
|
||||
f'Call CodeEvalService Error in `HumanevalXEvaluator`, The '
|
||||
f"results have been saved in path '{result_file_path}', You "
|
||||
'need to check that your code evaluate service is launched and'
|
||||
f' the network to service is connected, you can also get '
|
||||
f'results directly by using `curl` command refer to {ref_url}.'
|
||||
f'\nError Information: {output}')
|
||||
|
||||
def _code_eval_service(self, file_path):
|
||||
if self.port:
|
||||
eval_server_url = f'{self.ip_address}:{self.port}/evaluate'
|
||||
else:
|
||||
eval_server_url = f'{self.ip_address}/evaluate'
|
||||
exec_result = subprocess.run([
|
||||
'curl', '-X', 'POST', '-F', f'file=@{file_path}', '-F',
|
||||
f'dataset=humanevalx/{self.language}', f'{eval_server_url}'
|
||||
],
|
||||
timeout=self.timeout,
|
||||
capture_output=True)
|
||||
if exec_result.returncode == 0 and re.match(
|
||||
"\"{.*:.*}\"", exec_result.stdout.decode('utf-8')):
|
||||
return True, json.loads(exec_result.stdout.decode('utf-8'))
|
||||
else:
|
||||
if exec_result.stderr:
|
||||
try:
|
||||
err = exec_result.stderr.decode()
|
||||
except Exception:
|
||||
err = exec_result.stderr
|
||||
else:
|
||||
try:
|
||||
err = exec_result.stdout.decode()
|
||||
except Exception:
|
||||
err = exec_result.stdout
|
||||
return False, err
|
||||
|
||||
|
||||
def _clean_up_code(text: str, language_type: str, reference) -> str:
|
||||
"""Cleans up the generated code."""
|
||||
try:
|
||||
# for chatGLM related text
|
||||
eval_text = eval(text)
|
||||
except Exception:
|
||||
pass
|
||||
else:
|
||||
if isinstance(eval_text, str):
|
||||
text = eval_text
|
||||
# extract code from code block
|
||||
text = text.lstrip('\n')
|
||||
if '```' in text:
|
||||
blocks = re.findall(r'```(.*?)```', text, re.DOTALL)
|
||||
if len(blocks) == 0:
|
||||
text = text.split('```')[1] # fall back to default strategy
|
||||
else:
|
||||
text = blocks[0] # fetch the first code block
|
||||
if not text.startswith('\n'): # in case starting with ```xxx
|
||||
text = text[max(text.find('\n') + 1, 0):]
|
||||
if language_type.lower() == 'python':
|
||||
text = humaneval_postprocess_v2(text)
|
||||
# we need to take care of the first line
|
||||
# append extra space for first line for correct indentation
|
||||
text = ' ' + text.lstrip()
|
||||
|
||||
text_splits = text.split('\n')
|
||||
is_empty_line = False
|
||||
ind_empty_line = None
|
||||
for i, line in enumerate(text_splits):
|
||||
if len(line.strip()) > 0 and line[0] != ' ' and line[0] != '\t':
|
||||
is_empty_line = True
|
||||
ind_empty_line = i
|
||||
break
|
||||
if is_empty_line:
|
||||
text = '\n'.join(text_splits[:ind_empty_line])
|
||||
else:
|
||||
end_words = [
|
||||
'\ndef', '\nclass', '\n#', '\nassert', '\n"""', '\nprint',
|
||||
'\nif', '\n\n\n'
|
||||
]
|
||||
for w in end_words:
|
||||
if w in text:
|
||||
text = text[:text.rfind(w)]
|
||||
# strip function head for all other language
|
||||
func_name = reference.strip().split('\n')[-1]
|
||||
if func_name:
|
||||
func_name = func_name.strip().strip('{')
|
||||
if func_name in text:
|
||||
text = '\n'.join(text[text.find(func_name):].split('\n')[1:])
|
||||
if language_type.lower() == 'java':
|
||||
main_pos = text.find('public static void main')
|
||||
if main_pos != -1:
|
||||
text = text[:main_pos] + '}'
|
||||
if '}' in text:
|
||||
text = text[:text.rfind('}')] + '}'
|
||||
if text.count('{') + 1 == text.count('}'):
|
||||
text += '\n}'
|
||||
elif language_type.lower() == 'go':
|
||||
if '\nfunc main(' in text:
|
||||
text = text[:text.rfind('func main(')]
|
||||
if '}' in text:
|
||||
text = text[:text.rfind('}')] + '}'
|
||||
elif language_type.lower() == 'cpp':
|
||||
if '\nint main()' in text:
|
||||
text = text[:text.rfind('int main()')]
|
||||
if '}' in text:
|
||||
text = text[:text.rfind('}')] + '}'
|
||||
elif language_type.lower() == 'js':
|
||||
if '}' in text:
|
||||
text = text[:text.rfind('}')] + '}'
|
||||
elif language_type.lower() == 'rust':
|
||||
if '}' in text:
|
||||
text = text[:text.rfind('}')] + '}'
|
||||
|
||||
return text
|
||||
79
opencompass/datasets/PMMEval/mgsm.py
Executable file
79
opencompass/datasets/PMMEval/mgsm.py
Executable file
@ -0,0 +1,79 @@
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
|
||||
from datasets import Dataset
|
||||
|
||||
from opencompass.datasets.base import BaseDataset
|
||||
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
||||
from opencompass.registry import LOAD_DATASET
|
||||
from opencompass.utils import get_data_path
|
||||
|
||||
|
||||
def _get_last_digit(s):
|
||||
_PAT_LAST_DIGIT = re.compile(
|
||||
r'([+-])?(?=([0-9]|\.[0-9]))(0|([1-9](\d{0,2}(,\d{3})*)|\d*))?(\.\d*)?(?=\D|$)' # noqa E501
|
||||
)
|
||||
match = list(_PAT_LAST_DIGIT.finditer(s))
|
||||
if match:
|
||||
last_digit = match[-1].group().replace(',', '').replace(
|
||||
'+', '').strip().strip('.')
|
||||
# print(f"The last digit in {s} is {last_digit}")
|
||||
else:
|
||||
last_digit = None
|
||||
# logger.warning(f"No digits found in {s!r}")
|
||||
return last_digit
|
||||
|
||||
|
||||
@LOAD_DATASET.register_module()
|
||||
class PMMEvalMGSMDataset(BaseDataset):
|
||||
|
||||
@staticmethod
|
||||
def load(path: str, lang: str):
|
||||
data_path = get_data_path(path)
|
||||
|
||||
if os.environ.get('DATASET_SOURCE') == 'ModelScope':
|
||||
from modelscope import MsDataset
|
||||
dataset = MsDataset.load(dataset_name=data_path,
|
||||
subset_name='mgsm',
|
||||
split=f'test/{lang}')
|
||||
else:
|
||||
dataset = list()
|
||||
filename = os.path.join(data_path, f'mgsm/test/{lang}.jsonl')
|
||||
with open(filename, mode='r', encoding='utf-8') as f:
|
||||
for line in f:
|
||||
line = json.loads(line.strip())
|
||||
dataset.append(line)
|
||||
dataset = Dataset.from_list(dataset)
|
||||
|
||||
return dataset
|
||||
|
||||
|
||||
class PMMEvalMGSMEvaluator(BaseEvaluator):
|
||||
|
||||
def score(self, predictions, references):
|
||||
assert len(predictions) == len(references)
|
||||
|
||||
num_correct, total = 0, 0
|
||||
details = {}
|
||||
for index, (references_answer, predictions_answer) in enumerate(
|
||||
zip(references, predictions)):
|
||||
extracted_answer = _get_last_digit(predictions_answer)
|
||||
references_answer = references_answer.replace(',', '')
|
||||
if references_answer == extracted_answer:
|
||||
is_correct = True
|
||||
else:
|
||||
is_correct = False
|
||||
|
||||
num_correct += is_correct
|
||||
total += 1
|
||||
details[str(index)] = {
|
||||
'references': references_answer,
|
||||
'predictions': predictions_answer,
|
||||
'extracted': extracted_answer,
|
||||
'correct': is_correct,
|
||||
}
|
||||
|
||||
accuracy = round(num_correct / total * 100, 2)
|
||||
final_result = {'accuracy': accuracy, 'details': details}
|
||||
return final_result
|
||||
151
opencompass/datasets/PMMEval/mhellaswag.py
Executable file
151
opencompass/datasets/PMMEval/mhellaswag.py
Executable file
@ -0,0 +1,151 @@
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
from typing import Tuple
|
||||
|
||||
from datasets import Dataset
|
||||
|
||||
from opencompass.datasets.base import BaseDataset
|
||||
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
||||
from opencompass.registry import LOAD_DATASET, TEXT_POSTPROCESSORS
|
||||
from opencompass.utils import get_data_path
|
||||
|
||||
langs_dict = {
|
||||
'fr': ['La réponse est', 'la réponse est'],
|
||||
'en': ['the answer is', 'The answer is'],
|
||||
'vi': ['Câu trả lời là', 'câu trả lời là'],
|
||||
'ar': ['الجواب هو'],
|
||||
'th': ['คำตอบคือ'],
|
||||
'zh': ['答案是'],
|
||||
'ko': ['답변은'],
|
||||
'pt': ['A resposta é'],
|
||||
'ja': ['答えは'],
|
||||
'es': ['La respuesta es']
|
||||
}
|
||||
|
||||
|
||||
def extract_choice(gen, lang):
|
||||
r"""
|
||||
{
|
||||
"answer": "A|B|C|D"
|
||||
}
|
||||
"""
|
||||
patterns = [
|
||||
r"\{\s*?\"answer\"\s*?\:\s*?\"?(A|B|C|D).*?\"?\s*?\}",
|
||||
r"\{\s*?[\'\"]answer[\'\"]\s*?\:\s*?[\'\"](A|B|C|D).*?[\'\"]\s*?\}",
|
||||
r"\"answer\"\s*:\s*\"?(A|B|C|D)\"?",
|
||||
r"[\'\"]answer[\'\"]\s*:\s*[\'\"](A|B|C|D)[\'\"]"
|
||||
]
|
||||
for pattern in patterns:
|
||||
res = re.findall(pattern, gen, flags=re.DOTALL)
|
||||
if len(res) >= 1:
|
||||
return res[-1]
|
||||
|
||||
else:
|
||||
res = None
|
||||
pattern = langs_dict[lang]
|
||||
for p in pattern:
|
||||
if p in gen and p != gen:
|
||||
res = gen.split(p)
|
||||
if len(res) > 1 and len(res[-1].strip()) > 0:
|
||||
res = res[-1].strip()[0]
|
||||
else:
|
||||
res = None
|
||||
break
|
||||
|
||||
temp = ['A', 'B', 'C', 'D', 'a', 'b', 'c', 'd']
|
||||
if res in temp:
|
||||
return res
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
def extract_choice_fuzzy(gen, lang):
|
||||
options = ['A', 'B', 'C', 'D'] # 定义选项
|
||||
for option in options:
|
||||
if option in gen: # 检查选项是否在文本中
|
||||
return option # 返回第一个出现的选项
|
||||
return None
|
||||
|
||||
|
||||
@TEXT_POSTPROCESSORS.register_module('pmmeval_mhellaswag')
|
||||
def pmmeval_mhellaswag_postprocess(text: str, lang_code: str) -> Tuple[str]:
|
||||
return text, lang_code
|
||||
|
||||
|
||||
@LOAD_DATASET.register_module()
|
||||
class PMMEvalMHellaswagDataset(BaseDataset):
|
||||
|
||||
@staticmethod
|
||||
def load(path: str, lang: str):
|
||||
data_path = get_data_path(path)
|
||||
|
||||
if os.environ.get('DATASET_SOURCE') == 'ModelScope':
|
||||
from modelscope import MsDataset
|
||||
dataset = MsDataset.load(dataset_name=data_path,
|
||||
subset_name='mhellaswag',
|
||||
split=f'test/{lang}')
|
||||
else:
|
||||
dataset = list()
|
||||
filename = os.path.join(data_path, f'mhellaswag/test/{lang}.jsonl')
|
||||
with open(filename, mode='r', encoding='utf-8') as f:
|
||||
for line in f:
|
||||
line = json.loads(line.strip())
|
||||
dataset.append(line)
|
||||
dataset = Dataset.from_list(dataset)
|
||||
|
||||
return dataset
|
||||
|
||||
|
||||
class PMMEvalMHellaswagEvaluator(BaseEvaluator):
|
||||
|
||||
def score(self, predictions, references):
|
||||
assert len(predictions) == len(references)
|
||||
|
||||
all_results = list()
|
||||
|
||||
for (pred, lang), ref in zip(predictions, references):
|
||||
answer = chr(int(ref) + 65)
|
||||
choice = extract_choice(pred, lang)
|
||||
acc = 0
|
||||
failed_strict = 0
|
||||
failed = 1
|
||||
if choice is not None:
|
||||
failed = 0
|
||||
if answer.lower() == choice.lower():
|
||||
acc = 1
|
||||
else:
|
||||
acc = 0
|
||||
else:
|
||||
choice = extract_choice_fuzzy(pred, lang)
|
||||
if choice is None:
|
||||
acc = 0
|
||||
failed_strict = 1
|
||||
else:
|
||||
failed_strict = 0
|
||||
if answer.lower() == choice.lower():
|
||||
acc = 1
|
||||
else:
|
||||
acc = 0
|
||||
|
||||
all_results.append({
|
||||
'acc':
|
||||
float(acc),
|
||||
'failed':
|
||||
float(failed),
|
||||
'failed_strict':
|
||||
float(failed_strict),
|
||||
'extracted_answer':
|
||||
pred if pred else 'no answer',
|
||||
})
|
||||
|
||||
final_result = {
|
||||
'accuracy':
|
||||
round(
|
||||
sum(x['acc'] for x in all_results) / len(all_results) * 100,
|
||||
2),
|
||||
'details':
|
||||
all_results
|
||||
}
|
||||
|
||||
return final_result
|
||||
147
opencompass/datasets/PMMEval/mifeval.py
Executable file
147
opencompass/datasets/PMMEval/mifeval.py
Executable file
@ -0,0 +1,147 @@
|
||||
import json
|
||||
import os
|
||||
from typing import Tuple
|
||||
|
||||
from datasets import Dataset
|
||||
|
||||
from opencompass.datasets.base import BaseDataset
|
||||
from opencompass.datasets.PMMEval.mifeval_utils import mifeval_class_map
|
||||
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
||||
from opencompass.registry import LOAD_DATASET, TEXT_POSTPROCESSORS
|
||||
from opencompass.utils import get_data_path
|
||||
|
||||
|
||||
def test_instruction_following_strict(inp, response, lang_code):
|
||||
"""Tests response to see if instrutions are followed."""
|
||||
instruction_list = inp['instruction_id_list']
|
||||
is_following_list = []
|
||||
|
||||
for index, instruction_id in enumerate(instruction_list):
|
||||
instruction_id_0, instruction_id_1 = tuple(instruction_id.split(':'))
|
||||
instruction_fuction_info = mifeval_class_map[instruction_id_0][
|
||||
instruction_id_1]
|
||||
|
||||
instruction_function = instruction_fuction_info['function']
|
||||
instruction_function_args = dict()
|
||||
|
||||
if instruction_fuction_info['required_lang_code']:
|
||||
instruction_function_args['lang_code'] = lang_code
|
||||
for kwarg_dict in inp['kwargs']:
|
||||
for k, v in kwarg_dict.items():
|
||||
if v is None:
|
||||
continue
|
||||
instruction_function_args[k] = v
|
||||
instruction_function_args['input_string'] = response
|
||||
|
||||
if response.strip() and instruction_function(
|
||||
**instruction_function_args):
|
||||
is_following_list.append(True)
|
||||
else:
|
||||
is_following_list.append(False)
|
||||
|
||||
return 1.0 if all(is_following_list) else 0.0
|
||||
|
||||
|
||||
def test_instruction_following_loose(inp, response, lang_code):
|
||||
"""Tests response for an upper bound for following instructions."""
|
||||
r = response.split('\n')
|
||||
response_remove_first = '\n'.join(r[1:]).strip()
|
||||
response_remove_last = '\n'.join(r[:-1]).strip()
|
||||
response_remove_both = '\n'.join(r[1:-1]).strip()
|
||||
revised_response = response.replace('*', '')
|
||||
revised_response_remove_first = response_remove_first.replace('*', '')
|
||||
revised_response_remove_last = response_remove_last.replace('*', '')
|
||||
revised_response_remove_both = response_remove_both.replace('*', '')
|
||||
all_responses = [
|
||||
response,
|
||||
revised_response,
|
||||
response_remove_first,
|
||||
response_remove_last,
|
||||
response_remove_both,
|
||||
revised_response_remove_first,
|
||||
revised_response_remove_last,
|
||||
revised_response_remove_both,
|
||||
]
|
||||
instruction_list = inp['instruction_id_list']
|
||||
is_following_list = []
|
||||
|
||||
for index, instruction_id in enumerate(instruction_list):
|
||||
instruction_id_0, instruction_id_1 = tuple(instruction_id.split(':'))
|
||||
instruction_fuction_info = mifeval_class_map[instruction_id_0][
|
||||
instruction_id_1]
|
||||
|
||||
instruction_function = instruction_fuction_info['function']
|
||||
instruction_function_args = dict()
|
||||
|
||||
if instruction_fuction_info['required_lang_code']:
|
||||
instruction_function_args['lang_code'] = lang_code
|
||||
for kwarg_dict in inp['kwargs']:
|
||||
for k, v in kwarg_dict.items():
|
||||
instruction_function_args[k] = v
|
||||
instruction_function_args['input_string'] = response
|
||||
|
||||
is_following = False
|
||||
for r in all_responses:
|
||||
if r.strip() and instruction_function(**instruction_function_args):
|
||||
is_following = True
|
||||
break
|
||||
|
||||
is_following_list.append(is_following)
|
||||
|
||||
return 1.0 if all(is_following_list) else 0.0
|
||||
|
||||
|
||||
@TEXT_POSTPROCESSORS.register_module('pmmeval_mifeval')
|
||||
def pmmeval_mifeval_postprocess(text: str, lang_code: str) -> Tuple[str]:
|
||||
return text, lang_code
|
||||
|
||||
|
||||
@LOAD_DATASET.register_module()
|
||||
class PMMEvalMIFEvalDataset(BaseDataset):
|
||||
|
||||
@staticmethod
|
||||
def load(path: str, lang: str):
|
||||
data_path = get_data_path(path)
|
||||
|
||||
if os.environ.get('DATASET_SOURCE') == 'ModelScope':
|
||||
from modelscope import MsDataset
|
||||
dataset = MsDataset.load(dataset_name=data_path,
|
||||
subset_name='mifeval',
|
||||
split=f'test/{lang}')
|
||||
else:
|
||||
dataset = list()
|
||||
filename = os.path.join(data_path, f'mifeval/test/{lang}.jsonl')
|
||||
with open(filename, mode='r', encoding='utf-8') as f:
|
||||
for line in f:
|
||||
line = json.loads(line.strip())
|
||||
dataset.append(line)
|
||||
dataset = Dataset.from_list(dataset)
|
||||
|
||||
return dataset
|
||||
|
||||
|
||||
class PMMEvalMIFEvalEvaluator(BaseEvaluator):
|
||||
|
||||
def score(self, predictions, references, test_set):
|
||||
all_results = list()
|
||||
for (pred, lang), example in zip(predictions, test_set):
|
||||
temp_result = {
|
||||
'strict_acc':
|
||||
test_instruction_following_strict(example, pred, lang),
|
||||
'loose_acc':
|
||||
test_instruction_following_loose(example, pred, lang)
|
||||
}
|
||||
|
||||
all_results.append(temp_result)
|
||||
|
||||
result = {
|
||||
'strict_acc':
|
||||
round(
|
||||
sum(x['strict_acc']
|
||||
for x in all_results) / len(all_results) * 100, 2),
|
||||
'loose_acc':
|
||||
round(
|
||||
sum(x['loose_acc']
|
||||
for x in all_results) / len(all_results) * 100, 2)
|
||||
}
|
||||
return result
|
||||
17
opencompass/datasets/PMMEval/mifeval_utils/__init__.py
Executable file
17
opencompass/datasets/PMMEval/mifeval_utils/__init__.py
Executable file
@ -0,0 +1,17 @@
|
||||
from .combination_checker import combination_checker
|
||||
from .detectable_content_checker import detectable_content_checker
|
||||
from .detectable_format_checker import detectable_format_checker
|
||||
from .keywords_checker import keywords_checker
|
||||
from .length_constraints_checker import length_constraints_checker
|
||||
from .punctuation_checker import punctuation_checker
|
||||
from .startend_checker import startend_checker
|
||||
|
||||
mifeval_class_map = {
|
||||
'combination': combination_checker,
|
||||
'detectable_content': detectable_content_checker,
|
||||
'detectable_format': detectable_format_checker,
|
||||
'keywords': keywords_checker,
|
||||
'length_constraints': length_constraints_checker,
|
||||
'punctuation': punctuation_checker,
|
||||
'startend': startend_checker
|
||||
}
|
||||
32
opencompass/datasets/PMMEval/mifeval_utils/combination_checker.py
Executable file
32
opencompass/datasets/PMMEval/mifeval_utils/combination_checker.py
Executable file
@ -0,0 +1,32 @@
|
||||
def repeat_prompt_checker(input_string: str, prompt_to_repeat: str, **kwargs):
|
||||
if input_string.strip().lower().startswith(
|
||||
prompt_to_repeat.strip().lower()):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def two_responses_checker(input_string: str, **kwargs):
|
||||
valid_responses = list()
|
||||
responses = input_string.split('******')
|
||||
for index, response in enumerate(responses):
|
||||
if not response.strip():
|
||||
if index != 0 and index != len(responses) - 1:
|
||||
return False
|
||||
else:
|
||||
valid_responses.append(response)
|
||||
return (len(valid_responses) == 2
|
||||
and valid_responses[0].strip() != valid_responses[1].strip())
|
||||
|
||||
|
||||
combination_checker = {
|
||||
'repeat_prompt': {
|
||||
'function': repeat_prompt_checker,
|
||||
'required_lang_code': False,
|
||||
'num_of_params': 2
|
||||
},
|
||||
'two_responses': {
|
||||
'function': two_responses_checker,
|
||||
'required_lang_code': False,
|
||||
'num_of_params': 1
|
||||
}
|
||||
}
|
||||
30
opencompass/datasets/PMMEval/mifeval_utils/detectable_content_checker.py
Executable file
30
opencompass/datasets/PMMEval/mifeval_utils/detectable_content_checker.py
Executable file
@ -0,0 +1,30 @@
|
||||
import re
|
||||
|
||||
|
||||
def number_placeholders_checker(input_string: str, num_placeholders: int,
|
||||
**kwargs):
|
||||
placeholders = re.findall(r'\[.*?\]', input_string)
|
||||
return len(placeholders) >= num_placeholders
|
||||
|
||||
|
||||
def postscript_checker(input_string: str, postscript_marker: str, **kwargs):
|
||||
input_string = input_string.lower()
|
||||
postscript_pattern = r'\s*' + postscript_marker.lower() + r'.*$'
|
||||
postscript = re.findall(postscript_pattern,
|
||||
input_string,
|
||||
flags=re.MULTILINE)
|
||||
return True if postscript else False
|
||||
|
||||
|
||||
detectable_content_checker = {
|
||||
'number_placeholders': {
|
||||
'function': number_placeholders_checker,
|
||||
'required_lang_code': False,
|
||||
'num_of_params': 2
|
||||
},
|
||||
'postscript': {
|
||||
'function': postscript_checker,
|
||||
'required_lang_code': False,
|
||||
'num_of_params': 2
|
||||
}
|
||||
}
|
||||
122
opencompass/datasets/PMMEval/mifeval_utils/detectable_format_checker.py
Executable file
122
opencompass/datasets/PMMEval/mifeval_utils/detectable_format_checker.py
Executable file
@ -0,0 +1,122 @@
|
||||
import json
|
||||
import re
|
||||
|
||||
|
||||
def removeprefix(s, prefix):
|
||||
if s.startswith(prefix):
|
||||
return s[len(prefix):]
|
||||
else:
|
||||
return s
|
||||
|
||||
|
||||
def removesuffix(s, suffix):
|
||||
if s.endswith(suffix):
|
||||
return s[:-len(suffix)]
|
||||
else:
|
||||
return s
|
||||
|
||||
|
||||
constrained_response = {
|
||||
'ar': ['إجابتي هي نعم.', 'إجابتي هي لا.', 'إجابتي هي ربما.'],
|
||||
'es':
|
||||
['Mi respuesta es sí.', 'Mi respuesta es no.', 'Mi respuesta es tal vez.'],
|
||||
'fr': [
|
||||
'Ma réponse est oui.', 'Ma réponse est non.',
|
||||
'Ma réponse est peut-être.'
|
||||
],
|
||||
'ja': ['私の答えははいです。', '私の答えはいいえです。', '私の答えはたぶんです。'],
|
||||
'ko': ['제 대답은 예입니다.', '제 대답은 아닙니다.', '제 대답은 아마도입니다.'],
|
||||
'pt': [
|
||||
'Minha resposta é sim.', 'Minha resposta é não.',
|
||||
'Minha resposta é talvez.'
|
||||
],
|
||||
'th': ['คำตอบของฉันคือใช่', 'คำตอบของฉันคือไม่', 'คำตอบของฉันคืออาจจะ'],
|
||||
'vi': [
|
||||
'Câu trả lời của tôi là có.', 'Câu trả lời của tôi là không.',
|
||||
'Câu trả lời của tôi là có thể.'
|
||||
],
|
||||
'en': ['My answer is yes.', 'My answer is no.', 'My answer is maybe.'],
|
||||
'zh': ['我的答案是是。', '我的答案是否。', '我的答案是不确定。']
|
||||
}
|
||||
|
||||
|
||||
def constrained_response_checker(input_string: str, lang_code: str, **kwargs):
|
||||
allowable_responses = constrained_response[lang_code]
|
||||
return any(response in input_string for response in allowable_responses)
|
||||
|
||||
|
||||
def number_bullet_lists_checker(input_string: str, num_bullets: int, **kwargs):
|
||||
bullet_lists = re.findall(r'^\s*\*[^\*].*$',
|
||||
input_string,
|
||||
flags=re.MULTILINE)
|
||||
bullet_lists_2 = re.findall(r'^\s*-.*$', input_string, flags=re.MULTILINE)
|
||||
num_bullet_lists = len(bullet_lists) + len(bullet_lists_2)
|
||||
return num_bullet_lists == num_bullets
|
||||
|
||||
|
||||
def number_highlighted_sections_checker(input_string: str, num_highlights: int,
|
||||
**kwargs):
|
||||
temp_num_highlights = 0
|
||||
highlights = re.findall(r'\*[^\n\*]*\*', input_string)
|
||||
double_highlights = re.findall(r'\*\*[^\n\*]*\*\*', input_string)
|
||||
for highlight in highlights:
|
||||
if highlight.strip('*').strip():
|
||||
temp_num_highlights += 1
|
||||
for highlight in double_highlights:
|
||||
if removesuffix(removeprefix(highlight, '**'), '**').strip():
|
||||
temp_num_highlights += 1
|
||||
|
||||
return temp_num_highlights >= num_highlights
|
||||
|
||||
|
||||
def title_checker(input_string: str, **kwargs):
|
||||
pattern = r'<<[^\n]+>>'
|
||||
re_pattern = re.compile(pattern)
|
||||
titles = re.findall(re_pattern, input_string)
|
||||
|
||||
for title in titles:
|
||||
if title.lstrip('<').rstrip('>').strip():
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def json_format_checker(input_string: str, **kwargs):
|
||||
value = (removesuffix(
|
||||
removeprefix(
|
||||
removeprefix(
|
||||
removeprefix(removeprefix(input_string.strip(), '```json'),
|
||||
'```Json'), '```JSON'), '```'), '```').strip())
|
||||
try:
|
||||
json.loads(value)
|
||||
except ValueError as e: # noqa F841
|
||||
return False
|
||||
return True
|
||||
|
||||
|
||||
detectable_format_checker = {
|
||||
'constrained_response': {
|
||||
'function': constrained_response_checker,
|
||||
'required_lang_code': True,
|
||||
'num_of_params': 2
|
||||
},
|
||||
'json_format': {
|
||||
'function': json_format_checker,
|
||||
'required_lang_code': False,
|
||||
'num_of_params': 1
|
||||
},
|
||||
'number_bullet_lists': {
|
||||
'function': number_bullet_lists_checker,
|
||||
'required_lang_code': False,
|
||||
'num_of_parmas': 2
|
||||
},
|
||||
'number_highlighted_sections': {
|
||||
'function': number_highlighted_sections_checker,
|
||||
'required_lang_code': False,
|
||||
'num_of_params': 2
|
||||
},
|
||||
'title': {
|
||||
'function': title_checker,
|
||||
'required_lang_code': False,
|
||||
'num_of_params': 1
|
||||
}
|
||||
}
|
||||
12
opencompass/datasets/PMMEval/mifeval_utils/keywords_checker.py
Executable file
12
opencompass/datasets/PMMEval/mifeval_utils/keywords_checker.py
Executable file
@ -0,0 +1,12 @@
|
||||
def forbidden_words_checker(input_string: str, forbidden_words: list,
|
||||
**kwargs):
|
||||
return not any(word in input_string for word in forbidden_words)
|
||||
|
||||
|
||||
keywords_checker = {
|
||||
'forbidden_words': {
|
||||
'function': forbidden_words_checker,
|
||||
'required_lang_code': False,
|
||||
'num_of_params': 2
|
||||
},
|
||||
}
|
||||
93
opencompass/datasets/PMMEval/mifeval_utils/length_constraints_checker.py
Executable file
93
opencompass/datasets/PMMEval/mifeval_utils/length_constraints_checker.py
Executable file
@ -0,0 +1,93 @@
|
||||
import re
|
||||
|
||||
|
||||
def nth_paragraph_first_word_checker(input_string: str, num_paragraphs: int,
|
||||
nth_paragraph: int, first_word: str,
|
||||
lang_code: str, **kwargs):
|
||||
paragraphs = re.split(r'\n\n', input_string)
|
||||
paragraphs = list(paragraph.strip() for paragraph in paragraphs
|
||||
if paragraph.strip() != '')
|
||||
|
||||
if len(paragraphs) < num_paragraphs:
|
||||
return False
|
||||
|
||||
if len(paragraphs) < nth_paragraph:
|
||||
return False
|
||||
|
||||
paragraph = paragraphs[nth_paragraph - 1].strip()
|
||||
|
||||
first_word = ''
|
||||
|
||||
if paragraph.lower().startswith(first_word.lower()):
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
|
||||
def number_paragraphs_checker(input_string: str, num_paragraphs: int,
|
||||
**kwargs):
|
||||
paragraphs = re.split(r'\s?\*\*\*\s?', input_string)
|
||||
paragraphs = list(paragraph.strip() for paragraph in paragraphs
|
||||
if paragraph.strip() != '')
|
||||
return len(paragraphs) == num_paragraphs
|
||||
|
||||
|
||||
def number_sentences_checker(input_string: str, relation: str,
|
||||
num_sentences: int, lang_code: str, **kwargs):
|
||||
sentences = list(x.strip() for x in input_string.strip().split('\n'))
|
||||
sentences = list(x for x in sentences if x != '')
|
||||
|
||||
if relation == 'less than':
|
||||
if len(sentences) <= num_sentences:
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
elif relation == 'at least':
|
||||
if len(sentences) >= num_sentences:
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
|
||||
def number_words_checker(input_string: str, relation: str, num_words: int,
|
||||
lang_code: str, **kwargs):
|
||||
if lang_code in ['en', 'es', 'fr', 'in', 'pt', 'ru', 'vi']:
|
||||
words = input_string.split()
|
||||
words = list(x for x in words if x != '')
|
||||
else:
|
||||
words = ''.join(input_string.split())
|
||||
|
||||
if relation == 'less than':
|
||||
if len(words) <= num_words:
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
elif relation == 'at least':
|
||||
if len(words) >= num_words:
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
|
||||
length_constraints_checker = {
|
||||
'nth_paragraph_first_word': {
|
||||
'function': nth_paragraph_first_word_checker,
|
||||
'required_lang_code': True,
|
||||
'num_of_params': 5
|
||||
},
|
||||
'number_paragraphs': {
|
||||
'function': number_paragraphs_checker,
|
||||
'required_lang_code': False,
|
||||
'num_of_params': 2
|
||||
},
|
||||
'number_sentences': {
|
||||
'function': number_sentences_checker,
|
||||
'required_lang_code': True,
|
||||
'num_of_params': 3
|
||||
},
|
||||
'number_words': {
|
||||
'function': number_words_checker,
|
||||
'required_lang_code': True,
|
||||
'num_of_params': 4
|
||||
}
|
||||
}
|
||||
30
opencompass/datasets/PMMEval/mifeval_utils/punctuation_checker.py
Executable file
30
opencompass/datasets/PMMEval/mifeval_utils/punctuation_checker.py
Executable file
@ -0,0 +1,30 @@
|
||||
import re
|
||||
|
||||
comma_unicode = {
|
||||
'ar': re.compile(r'[\u060C]'),
|
||||
'es': re.compile(r'[,\uFF0C]'),
|
||||
'fr': re.compile(r'[,\u2026]'),
|
||||
'ja': re.compile(r'[,\u3001]'),
|
||||
'ko': re.compile(r'[,]'),
|
||||
'pt': re.compile(r'[,\uFF0C]'),
|
||||
'th': re.compile(r'[\u0E25]'),
|
||||
'vi': re.compile(r'[,\uFF0C]'),
|
||||
'en': re.compile(r'[,]'),
|
||||
'zh': re.compile(r'[,,]')
|
||||
}
|
||||
|
||||
|
||||
def no_comma_checker(input_string: str, lang_code: str, **kwargs):
|
||||
if len(comma_unicode[lang_code].findall(input_string)) > 0:
|
||||
return False
|
||||
else:
|
||||
return True
|
||||
|
||||
|
||||
punctuation_checker = {
|
||||
'no_comma': {
|
||||
'function': no_comma_checker,
|
||||
'required_lang_code': True,
|
||||
'num_of_params': 2
|
||||
}
|
||||
}
|
||||
38
opencompass/datasets/PMMEval/mifeval_utils/startend_checker.py
Executable file
38
opencompass/datasets/PMMEval/mifeval_utils/startend_checker.py
Executable file
@ -0,0 +1,38 @@
|
||||
def end_checker_checker(input_string: str, end_phrase: str, **kwargs):
|
||||
if input_string.strip().endswith(end_phrase):
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
|
||||
def quotation_checker(input_string: str, lang_code: str, **kwargs):
|
||||
input_string = input_string.strip()
|
||||
if input_string.startswith('"') and input_string.endswith('"'):
|
||||
return True
|
||||
elif lang_code in [
|
||||
'ar', 'es', 'fr', 'pt', 'ru'
|
||||
] and input_string.startswith('«') and input_string.endswith('»'):
|
||||
return True
|
||||
elif lang_code in [
|
||||
'ar', 'es', 'fr', 'ko', 'pt', 'th', 'vi', 'zh'
|
||||
] and input_string.startswith('“') and input_string.endswith('”'):
|
||||
return True
|
||||
elif lang_code == 'ja' and input_string.startswith(
|
||||
'『') and input_string.endswith('』'):
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
|
||||
startend_checker = {
|
||||
'end_checker': {
|
||||
'function': end_checker_checker,
|
||||
'required_lang_code': False,
|
||||
'num_of_params': 2
|
||||
},
|
||||
'quotation': {
|
||||
'function': quotation_checker,
|
||||
'required_lang_code': True,
|
||||
'num_of_params': 2
|
||||
}
|
||||
}
|
||||
152
opencompass/datasets/PMMEval/mlogiqa.py
Executable file
152
opencompass/datasets/PMMEval/mlogiqa.py
Executable file
@ -0,0 +1,152 @@
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
from typing import Tuple
|
||||
|
||||
from datasets import Dataset
|
||||
|
||||
from opencompass.datasets.base import BaseDataset
|
||||
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
||||
from opencompass.registry import LOAD_DATASET, TEXT_POSTPROCESSORS
|
||||
from opencompass.utils import get_data_path
|
||||
|
||||
langs_dict = {
|
||||
'fr': ['La réponse est', 'la réponse est'],
|
||||
'en': ['the answer is', 'The answer is'],
|
||||
'vi': ['Câu trả lời là', 'câu trả lời là'],
|
||||
'ar': ['الجواب هو'],
|
||||
'th': ['คำตอบคือ'],
|
||||
'zh': ['答案是'],
|
||||
'ko': ['답변은'],
|
||||
'pt': ['A resposta é'],
|
||||
'ja': ['答えは'],
|
||||
'es': ['La respuesta es']
|
||||
}
|
||||
|
||||
|
||||
def extract_choice(gen, lang):
|
||||
r"""
|
||||
{
|
||||
"answer": "A|B|C|D"
|
||||
}
|
||||
"""
|
||||
patterns = [
|
||||
r"\{\s*?\"answer\"\s*?\:\s*?\"?(A|B|C|D).*?\"?\s*?\}",
|
||||
r"\{\s*?[\'\"]answer[\'\"]\s*?\:\s*?[\'\"](A|B|C|D).*?[\'\"]\s*?\}",
|
||||
r"\"answer\"\s*:\s*\"?(A|B|C|D)\"?",
|
||||
r"[\'\"]answer[\'\"]\s*:\s*[\'\"](A|B|C|D)[\'\"]"
|
||||
]
|
||||
for pattern in patterns:
|
||||
res = re.findall(pattern, gen, flags=re.DOTALL)
|
||||
if len(res) >= 1:
|
||||
return res[-1]
|
||||
|
||||
else:
|
||||
res = None
|
||||
pattern = langs_dict[lang]
|
||||
for p in pattern:
|
||||
if p in gen and p != gen:
|
||||
res = gen.split(p)
|
||||
if len(res) > 1 and len(res[-1].strip()) > 0:
|
||||
res = res[-1].strip()[0]
|
||||
else:
|
||||
res = None
|
||||
|
||||
break
|
||||
|
||||
temp = ['A', 'B', 'C', 'D', 'a', 'b', 'c', 'd']
|
||||
if res in temp:
|
||||
return res
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
def extract_choice_fuzzy(gen):
|
||||
options = ['A', 'B', 'C', 'D']
|
||||
for option in options:
|
||||
if option in gen:
|
||||
return option
|
||||
return None
|
||||
|
||||
|
||||
@TEXT_POSTPROCESSORS.register_module('pmmeval_mlogiqa')
|
||||
def pmmeval_mlogiqa_postprocess(text: str, lang_code: str) -> Tuple[str]:
|
||||
return text, lang_code
|
||||
|
||||
|
||||
@LOAD_DATASET.register_module()
|
||||
class PMMEvalMLogiQADataset(BaseDataset):
|
||||
|
||||
@staticmethod
|
||||
def load(path: str, lang: str):
|
||||
data_path = get_data_path(path)
|
||||
|
||||
if os.environ.get('DATASET_SOURCE') == 'ModelScope':
|
||||
from modelscope import MsDataset
|
||||
dataset = MsDataset.load(dataset_name=data_path,
|
||||
subset_name='mlogiqa',
|
||||
split=f'test/{lang}')
|
||||
else:
|
||||
dataset = list()
|
||||
filename = os.path.join(data_path, f'mlogiqa/test/{lang}.jsonl')
|
||||
with open(filename, mode='r', encoding='utf-8') as f:
|
||||
for line in f:
|
||||
line = json.loads(line.strip())
|
||||
dataset.append(line)
|
||||
dataset = Dataset.from_list(dataset)
|
||||
|
||||
return dataset
|
||||
|
||||
|
||||
class PMMEvalMLogiQAEvaluator(BaseEvaluator):
|
||||
|
||||
def score(self, predictions, references):
|
||||
assert len(predictions) == len(references)
|
||||
|
||||
all_results = list()
|
||||
|
||||
for (pred, lang), ref in zip(predictions, references):
|
||||
answer = chr(int(ref) + 65)
|
||||
pred = extract_choice(pred, lang)
|
||||
acc = 0
|
||||
failed_strict = 0
|
||||
failed = 1
|
||||
if pred is not None:
|
||||
failed = 0
|
||||
if answer.lower() == pred.lower():
|
||||
acc = 1
|
||||
else:
|
||||
acc = 0
|
||||
else:
|
||||
pred_fuzzy = extract_choice_fuzzy(pred)
|
||||
if pred_fuzzy is None:
|
||||
acc = 0
|
||||
failed_strict = 1
|
||||
else:
|
||||
failed_strict = 0
|
||||
if answer.lower() == pred_fuzzy.lower():
|
||||
acc = 1
|
||||
else:
|
||||
acc = 0
|
||||
|
||||
all_results.append({
|
||||
'acc':
|
||||
float(acc),
|
||||
'failed':
|
||||
float(failed),
|
||||
'failed_strict':
|
||||
float(failed_strict),
|
||||
'extracted_answer':
|
||||
pred if pred else 'no answer',
|
||||
})
|
||||
|
||||
final_result = {
|
||||
'accuracy':
|
||||
round(
|
||||
sum(x['acc'] for x in all_results) / len(all_results) * 100,
|
||||
2),
|
||||
'details':
|
||||
all_results
|
||||
}
|
||||
|
||||
return final_result
|
||||
157
opencompass/datasets/PMMEval/mmmlu.py
Executable file
157
opencompass/datasets/PMMEval/mmmlu.py
Executable file
@ -0,0 +1,157 @@
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
from typing import Tuple
|
||||
|
||||
from datasets import Dataset
|
||||
|
||||
from opencompass.datasets.base import BaseDataset
|
||||
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
||||
from opencompass.registry import LOAD_DATASET, TEXT_POSTPROCESSORS
|
||||
from opencompass.utils import get_data_path
|
||||
|
||||
langs_dict = {
|
||||
'FR-FR': ['La réponse est', 'la réponse est'],
|
||||
'EN-US': ['the answer is', 'The answer is'],
|
||||
'VI-VT': ['Câu trả lời là', 'câu trả lời là'],
|
||||
'AR-XY': ['الجواب هو'],
|
||||
'TH-TL': ['คำตอบคือ'],
|
||||
'ZH-CN': ['答案是'],
|
||||
'KO-KR': ['답변은'],
|
||||
'PT-BR': ['A resposta é'],
|
||||
'JA-JP': ['答えは'],
|
||||
'ES-LA': ['La respuesta es']
|
||||
}
|
||||
|
||||
|
||||
def extract_choice(gen, lang):
|
||||
r"""
|
||||
{
|
||||
"answer": "A|B|C|D"
|
||||
}
|
||||
"""
|
||||
patterns = [
|
||||
r"\{\s*?\"answer\"\s*?\:\s*?\"?(A|B|C|D).*?\"?\s*?\}",
|
||||
r"\{\s*?[\'\"]answer[\'\"]\s*?\:\s*?[\'\"](A|B|C|D).*?[\'\"]\s*?\}",
|
||||
r"\"answer\"\s*:\s*\"?(A|B|C|D)\"?",
|
||||
r"[\'\"]answer[\'\"]\s*:\s*[\'\"](A|B|C|D)[\'\"]"
|
||||
]
|
||||
for pattern in patterns:
|
||||
res = re.findall(pattern, gen, flags=re.DOTALL)
|
||||
if len(res) >= 1:
|
||||
return res[-1]
|
||||
|
||||
else:
|
||||
res = None
|
||||
pattern = langs_dict[lang]
|
||||
for p in pattern:
|
||||
if p in gen and p != gen:
|
||||
res = gen.split(p)
|
||||
if len(res) > 1 and len(res[-1].strip()) > 0:
|
||||
res = res[-1].strip()[0]
|
||||
else:
|
||||
res = None
|
||||
break
|
||||
|
||||
temp = ['A', 'B', 'C', 'D', 'a', 'b', 'c', 'd']
|
||||
if res in temp:
|
||||
return res
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
def extract_choice_fuzzy(gen):
|
||||
options = ['A', 'B', 'C', 'D']
|
||||
for option in options:
|
||||
if option in gen:
|
||||
return option
|
||||
return None
|
||||
|
||||
|
||||
@TEXT_POSTPROCESSORS.register_module('pmmeval_mmmlu')
|
||||
def pmmeval_mmmlu_postprocess(text: str, lang_code: str) -> Tuple[str]:
|
||||
return text, lang_code
|
||||
|
||||
|
||||
@LOAD_DATASET.register_module()
|
||||
class PMMEvalMMMLUDataset(BaseDataset):
|
||||
|
||||
@staticmethod
|
||||
def load(path: str, lang: str, difficulty: str):
|
||||
assert difficulty in [
|
||||
'easy', 'hard', 'all'
|
||||
], '`difficulty` should be one choice among "easy", "hard", and "all"!'
|
||||
data_path = get_data_path(path)
|
||||
|
||||
if os.environ.get('DATASET_SOURCE') == 'ModelScope':
|
||||
dataset_list = list()
|
||||
from modelscope import MsDataset
|
||||
if difficulty == 'easy' or difficulty == 'all':
|
||||
dataset_list.append(
|
||||
MsDataset.load(dataset_name=data_path,
|
||||
subset_name='mmmlu',
|
||||
split=f'easy/test/mmlu_{lang}'))
|
||||
if difficulty == 'hard' or difficulty == 'all':
|
||||
dataset_list.append(
|
||||
MsDataset.load(dataset_name=data_path,
|
||||
subset_name='mmmlu',
|
||||
split=f'hard/test/mmlu_{lang}'))
|
||||
# TODO: conbine two datasets
|
||||
dataset = dataset_list[0] + dataset_list[1] if len(
|
||||
dataset_list) == 2 else dataset_list[0]
|
||||
else:
|
||||
dataset = list()
|
||||
if difficulty == 'easy' or difficulty == 'all':
|
||||
filename = os.path.join(data_path,
|
||||
f'mmmlu/easy/test/mmlu_{lang}.jsonl')
|
||||
with open(filename, mode='r', encoding='utf-8') as f:
|
||||
for line in f:
|
||||
line = json.loads(line.strip())
|
||||
dataset.append(line)
|
||||
if difficulty == 'hard' or difficulty == 'all':
|
||||
filename = os.path.join(data_path,
|
||||
f'mmmlu/hard/test/mmlu_{lang}.jsonl')
|
||||
with open(filename, mode='r', encoding='utf-8') as f:
|
||||
for line in f:
|
||||
line = json.loads(line.strip())
|
||||
dataset.append(line)
|
||||
|
||||
dataset = Dataset.from_list(dataset)
|
||||
|
||||
return dataset
|
||||
|
||||
|
||||
class PMMEvalMMMLUEvaluator(BaseEvaluator):
|
||||
|
||||
def score(self, predictions, references):
|
||||
all_results = list()
|
||||
for (pred, lang), ref in zip(predictions, references):
|
||||
answer = extract_choice(pred, lang)
|
||||
if answer is None:
|
||||
answer = extract_choice_fuzzy(pred)
|
||||
if answer is None:
|
||||
acc = 0.0
|
||||
failed = 1.0
|
||||
else:
|
||||
acc = 1.0 if ref.lower() == answer.lower() else 0.0
|
||||
failed = 0.0
|
||||
|
||||
all_results.append({
|
||||
'acc':
|
||||
acc,
|
||||
'failed':
|
||||
failed,
|
||||
'extracted_answer':
|
||||
pred if pred else 'no answer'
|
||||
})
|
||||
|
||||
final_result = {
|
||||
'accuracy':
|
||||
round(
|
||||
sum(x['acc'] for x in all_results) / len(all_results) * 100,
|
||||
2),
|
||||
'details':
|
||||
all_results
|
||||
}
|
||||
|
||||
return final_result
|
||||
150
opencompass/datasets/PMMEval/xnli.py
Executable file
150
opencompass/datasets/PMMEval/xnli.py
Executable file
@ -0,0 +1,150 @@
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
from typing import Tuple
|
||||
|
||||
from datasets import Dataset
|
||||
|
||||
from opencompass.datasets.base import BaseDataset
|
||||
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
||||
from opencompass.registry import LOAD_DATASET, TEXT_POSTPROCESSORS
|
||||
from opencompass.utils import get_data_path
|
||||
|
||||
langs_dict = {
|
||||
'fr': ['La réponse est', 'la réponse est'],
|
||||
'en': ['the answer is', 'The answer is'],
|
||||
'vi': ['Câu trả lời là', 'câu trả lời là'],
|
||||
'ar': ['الجواب هو'],
|
||||
'th': ['คำตอบคือ'],
|
||||
'zh': ['答案是'],
|
||||
'ko': ['답변은'],
|
||||
'pt': ['A resposta é'],
|
||||
'ja': ['答えは'],
|
||||
'id': ['Jawaban adalah', 'jawaban adalah'],
|
||||
'es': ['La respuesta es']
|
||||
}
|
||||
|
||||
|
||||
def extract_choice(gen, lang):
|
||||
r"""
|
||||
{
|
||||
"answer": "A|B|C|D"
|
||||
}
|
||||
"""
|
||||
patterns = [
|
||||
r"\{\s*?\"answer\"\s*?\:\s*?\"?(A|B|C|D).*?\"?\s*?\}",
|
||||
r"\{\s*?[\'\"]answer[\'\"]\s*?\:\s*?[\'\"](A|B|C|D).*?[\'\"]\s*?\}",
|
||||
r"\"answer\"\s*:\s*\"?(A|B|C|D)\"?",
|
||||
r"[\'\"]answer[\'\"]\s*:\s*[\'\"](A|B|C|D)[\'\"]"
|
||||
]
|
||||
for pattern in patterns:
|
||||
res = re.findall(pattern, gen, flags=re.DOTALL)
|
||||
if len(res) >= 1:
|
||||
return res[-1]
|
||||
|
||||
else:
|
||||
res = None
|
||||
pattern = langs_dict[lang]
|
||||
for p in pattern:
|
||||
if p in gen and p != gen:
|
||||
res = gen.split(p)
|
||||
if len(res) > 1 and len(res[-1].strip()) > 0:
|
||||
res = res[-1].strip()[0]
|
||||
else:
|
||||
res = None
|
||||
break
|
||||
|
||||
temp = ['A', 'B', 'C', 'D', 'a', 'b', 'c', 'd']
|
||||
if res in temp:
|
||||
return res
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
def extract_choice_fuzzy(gen, lang):
|
||||
options = ['A', 'B', 'C', 'D'] # 定义选项
|
||||
for option in options:
|
||||
if option in gen: # 检查选项是否在文本中
|
||||
return option # 返回第一个出现的选项
|
||||
return None
|
||||
|
||||
|
||||
@TEXT_POSTPROCESSORS.register_module('pmmeval_xnli')
|
||||
def pmmeval_xnli_postprocess(text: str, lang_code: str) -> Tuple[str]:
|
||||
return text, lang_code
|
||||
|
||||
|
||||
@LOAD_DATASET.register_module()
|
||||
class PMMEvalXNLIDataset(BaseDataset):
|
||||
|
||||
@staticmethod
|
||||
def load(path: str, lang: str):
|
||||
data_path = get_data_path(path)
|
||||
if os.environ.get('DATASET_SOURCE') == 'ModelScope':
|
||||
from modelscope import MsDataset
|
||||
dataset = MsDataset.load(dataset_name=data_path,
|
||||
subset_name='xnli',
|
||||
split=f'test/{lang}')
|
||||
else:
|
||||
dataset = list()
|
||||
filename = os.path.join(data_path, f'xnli/test/{lang}.jsonl')
|
||||
with open(filename, mode='r', encoding='utf-8') as f:
|
||||
for line in f:
|
||||
line = json.loads(line.strip())
|
||||
dataset.append(line)
|
||||
dataset = Dataset.from_list(dataset)
|
||||
|
||||
return dataset
|
||||
|
||||
|
||||
class PMMEvalXNLIEvaluator(BaseEvaluator):
|
||||
|
||||
def score(self, predictions, references):
|
||||
assert len(predictions) == len(references)
|
||||
|
||||
all_results = list()
|
||||
|
||||
for (pred, lang), ref in zip(predictions, references):
|
||||
choice = extract_choice(pred, lang)
|
||||
acc = 0
|
||||
failed_strict = 0
|
||||
failed = 1
|
||||
if choice is not None:
|
||||
failed = 0
|
||||
if ref.lower() == choice.lower():
|
||||
acc = 1
|
||||
else:
|
||||
acc = 0
|
||||
else:
|
||||
choice = extract_choice_fuzzy(pred, lang)
|
||||
if choice is None:
|
||||
acc = 0
|
||||
failed_strict = 1
|
||||
else:
|
||||
failed_strict = 0
|
||||
if ref.lower() == choice.lower():
|
||||
acc = 1
|
||||
else:
|
||||
acc = 0
|
||||
|
||||
all_results.append({
|
||||
'acc':
|
||||
float(acc),
|
||||
'failed':
|
||||
float(failed),
|
||||
'failed_strict':
|
||||
float(failed_strict),
|
||||
'extracted_answer':
|
||||
choice if choice else 'no answer',
|
||||
})
|
||||
|
||||
final_result = {
|
||||
'accuracy':
|
||||
round(
|
||||
sum(x['acc'] for x in all_results) / len(all_results) * 100,
|
||||
2),
|
||||
'details':
|
||||
all_results
|
||||
}
|
||||
|
||||
return final_result
|
||||
@ -6,6 +6,7 @@ from .anli import AnliDataset # noqa: F401, F403
|
||||
from .anthropics_evals import * # noqa: F401, F403
|
||||
from .apps import * # noqa: F401, F403
|
||||
from .arc import * # noqa: F401, F403
|
||||
from .arc_prize_public_evaluation import * # noqa: F401, F403
|
||||
from .ax import * # noqa: F401, F403
|
||||
from .babilong import * # noqa: F401, F403
|
||||
from .bbh import * # noqa: F401, F403
|
||||
@ -65,6 +66,7 @@ from .iwslt2017 import * # noqa: F401, F403
|
||||
from .jigsawmultilingual import * # noqa: F401, F403
|
||||
from .jsonl import JsonlDataset # noqa: F401, F403
|
||||
from .kaoshi import KaoshiDataset, KaoshiEvaluator # noqa: F401, F403
|
||||
from .korbench import * # noqa: F401, F403
|
||||
from .lambada import * # noqa: F401, F403
|
||||
from .lawbench import * # noqa: F401, F403
|
||||
from .LCBench import * # noqa: F401, F403
|
||||
@ -107,6 +109,7 @@ from .ruler import * # noqa: F401, F403
|
||||
from .safety import * # noqa: F401, F403
|
||||
from .scibench import ScibenchDataset, scibench_postprocess # noqa: F401, F403
|
||||
from .scicode import * # noqa: F401, F403
|
||||
from .simpleqa import * # noqa: F401, F403
|
||||
from .siqa import * # noqa: F401, F403
|
||||
from .squad20 import SQuAD20Dataset, SQuAD20Evaluator # noqa: F401, F403
|
||||
from .storycloze import * # noqa: F401, F403
|
||||
|
||||
213
opencompass/datasets/arc_prize_public_evaluation.py
Normal file
213
opencompass/datasets/arc_prize_public_evaluation.py
Normal file
@ -0,0 +1,213 @@
|
||||
import ast
|
||||
import json
|
||||
import os
|
||||
from typing import Dict, List
|
||||
|
||||
import numpy as np
|
||||
from datasets import Dataset
|
||||
|
||||
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
||||
from opencompass.registry import LOAD_DATASET
|
||||
from opencompass.utils import get_data_path
|
||||
|
||||
from .base import BaseDataset
|
||||
|
||||
|
||||
@LOAD_DATASET.register_module()
|
||||
class ARCPrizeDataset(BaseDataset):
|
||||
task_file_names = [
|
||||
'2072aba6.json', 'bb52a14b.json', '136b0064.json', 'ea9794b1.json',
|
||||
'40f6cd08.json', 'f5aa3634.json', '7039b2d7.json', '712bf12e.json',
|
||||
'9b365c51.json', 'ccd554ac.json', 'f9d67f8b.json', '03560426.json',
|
||||
'e2092e0c.json', '8fbca751.json', '42918530.json', 'c64f1187.json',
|
||||
'00576224.json', '705a3229.json', 'af24b4cc.json', '81c0276b.json',
|
||||
'f21745ec.json', '8dae5dfc.json', '4e469f39.json', '695367ec.json',
|
||||
'dc2aa30b.json', 'b9630600.json', '770cc55f.json', '3391f8c0.json',
|
||||
'c1990cce.json', '1da012fc.json', '50a16a69.json', '212895b5.json',
|
||||
'e69241bd.json', '692cd3b6.json', '0bb8deee.json', '9772c176.json',
|
||||
'22a4bbc2.json', 'ca8de6ea.json', 'dc2e9a9d.json', '4aab4007.json',
|
||||
'cfb2ce5a.json', '9f27f097.json', '2c737e39.json', '84db8fc4.json',
|
||||
'e1baa8a4.json', 'ea959feb.json', '4f537728.json', '47996f11.json',
|
||||
'bf32578f.json', 'aee291af.json', '5d2a5c43.json', '2546ccf6.json',
|
||||
'e57337a4.json', 'd4b1c2b1.json', '20981f0e.json', '05a7bcf2.json',
|
||||
'fc754716.json', '6ad5bdfd.json', 'e88171ec.json', '1acc24af.json',
|
||||
'34b99a2b.json', 'e78887d1.json', '4acc7107.json', '137f0df0.json',
|
||||
'62b74c02.json', '50aad11f.json', '642d658d.json', '64a7c07e.json',
|
||||
'bd14c3bf.json', '73c3b0d8.json', 'e0fb7511.json', 'c7d4e6ad.json',
|
||||
'85b81ff1.json', 'e760a62e.json', 'ca8f78db.json', 'd931c21c.json',
|
||||
'aab50785.json', 'ac605cbb.json', '3194b014.json', '68b67ca3.json',
|
||||
'e7b06bea.json', 'e5790162.json', 'da2b0fe3.json', '0becf7df.json',
|
||||
'fe9372f3.json', 'd56f2372.json', 'e66aafb8.json', 'b7999b51.json',
|
||||
'2697da3f.json', '516b51b7.json', '9a4bb226.json', '195ba7dc.json',
|
||||
'310f3251.json', '639f5a19.json', '0d87d2a6.json', 'c663677b.json',
|
||||
'e74e1818.json', '69889d6e.json', 'f45f5ca7.json', '8597cfd7.json',
|
||||
'0c9aba6e.json', 'e9b4f6fc.json', 'e7639916.json', '5207a7b5.json',
|
||||
'e4075551.json', '90347967.json', '9ddd00f0.json', '4b6b68e5.json',
|
||||
'e9c9d9a1.json', '2f0c5170.json', '58e15b12.json', 'd37a1ef5.json',
|
||||
'62ab2642.json', 'b457fec5.json', 'c97c0139.json', 'ac0c5833.json',
|
||||
'7d419a02.json', '4ff4c9da.json', '4cd1b7b2.json', '27a77e38.json',
|
||||
'66f2d22f.json', '2a5f8217.json', 'c074846d.json', 'c6e1b8da.json',
|
||||
'319f2597.json', '94be5b80.json', '55783887.json', '60c09cac.json',
|
||||
'f823c43c.json', 'd492a647.json', 'e681b708.json', '15663ba9.json',
|
||||
'a3f84088.json', '103eff5b.json', '5a5a2103.json', '1e97544e.json',
|
||||
'009d5c81.json', 'ed74f2f2.json', 'ce039d91.json', 'baf41dbf.json',
|
||||
'3490cc26.json', 'ce8d95cc.json', '3f23242b.json', '1d0a4b61.json',
|
||||
'8719f442.json', 'd94c3b52.json', '4c177718.json', '59341089.json',
|
||||
'3ee1011a.json', 'f5c89df1.json', '5833af48.json', 'd4c90558.json',
|
||||
'88207623.json', '833dafe3.json', '070dd51e.json', '3ed85e70.json',
|
||||
'21f83797.json', '7c8af763.json', '5783df64.json', 'a57f2f04.json',
|
||||
'e9ac8c9e.json', 'aa18de87.json', '505fff84.json', '5ffb2104.json',
|
||||
'42a15761.json', '1a2e2828.json', '0607ce86.json', '84f2aca1.json',
|
||||
'456873bc.json', '903d1b4a.json', '0f63c0b9.json', '54db823b.json',
|
||||
'ad7e01d0.json', '8e2edd66.json', '79fb03f4.json', '4364c1c4.json',
|
||||
'e7a25a18.json', 'e133d23d.json', 'e21a174a.json', '55059096.json',
|
||||
'e95e3d8e.json', '94414823.json', '9356391f.json', '15113be4.json',
|
||||
'ba9d41b8.json', '52fd389e.json', 'de493100.json', '9c56f360.json',
|
||||
'c92b942c.json', '97239e3d.json', 'b0f4d537.json', '19bb5feb.json',
|
||||
'506d28a5.json', '5b692c0f.json', 'ef26cbf6.json', 'e345f17b.json',
|
||||
'7d1f7ee8.json', 'ac3e2b04.json', '551d5bf1.json', 'fb791726.json',
|
||||
'2037f2c7.json', 'e6de6e8f.json', '3d31c5b3.json', 'd19f7514.json',
|
||||
'1d398264.json', '358ba94e.json', '696d4842.json', '08573cc6.json',
|
||||
'7e02026e.json', '7953d61e.json', 'c3202e5a.json', '351d6448.json',
|
||||
'fea12743.json', '12422b43.json', 'b942fd60.json', 'bcb3040b.json',
|
||||
'e41c6fd3.json', 'a59b95c0.json', '3a301edc.json', '0b17323b.json',
|
||||
'da515329.json', '96a8c0cd.json', '6f473927.json', '9def23fe.json',
|
||||
'c35c1b4c.json', 'be03b35f.json', '604001fa.json', 'd304284e.json',
|
||||
'cb227835.json', 'e9bb6954.json', 'ac2e8ecf.json', '1e81d6f9.json',
|
||||
'72207abc.json', '37d3e8b2.json', 'c8b7cc0f.json', 'a096bf4d.json',
|
||||
'1c02dbbe.json', 'fd096ab6.json', '9bebae7a.json', '25094a63.json',
|
||||
'b7fb29bc.json', 'aa4ec2a5.json', '50f325b5.json', '423a55dc.json',
|
||||
'b0722778.json', 'e7dd8335.json', 'f3cdc58f.json', 'cad67732.json',
|
||||
'256b0a75.json', 'd282b262.json', '58743b76.json', '6df30ad6.json',
|
||||
'9110e3c5.json', '48f8583b.json', 'a680ac02.json', '642248e4.json',
|
||||
'2685904e.json', '48131b3c.json', 'b7cb93ac.json', '73182012.json',
|
||||
'df8cc377.json', '3b4c2228.json', '93c31fbe.json', '8ee62060.json',
|
||||
'9b2a60aa.json', 'f0df5ff0.json', '917bccba.json', 'ed98d772.json',
|
||||
'bf89d739.json', 'f3e62deb.json', '11e1fe23.json', 'bbb1b8b6.json',
|
||||
'f4081712.json', '817e6c09.json', '45bbe264.json', 'f3b10344.json',
|
||||
'fafd9572.json', 'b7f8a4d8.json', '2c0b0aff.json', '8cb8642d.json',
|
||||
'67c52801.json', 'd47aa2ff.json', '0934a4d8.json', '60a26a3e.json',
|
||||
'cf133acc.json', '5289ad53.json', '16b78196.json', '09c534e7.json',
|
||||
'f83cb3f6.json', 'd017b73f.json', 'b20f7c8b.json', '5af49b42.json',
|
||||
'18419cfa.json', '929ab4e9.json', '6a11f6da.json', '17cae0c1.json',
|
||||
'e99362f0.json', '1c56ad9f.json', '8a371977.json', 'e633a9e5.json',
|
||||
'c658a4bd.json', 'bc4146bd.json', '67636eac.json', '4e45f183.json',
|
||||
'17b80ad2.json', '94133066.json', 'e1d2900e.json', 'a934301b.json',
|
||||
'0a2355a6.json', '45737921.json', '332efdb3.json', '7bb29440.json',
|
||||
'f9a67cb5.json', 'a8610ef7.json', '32e9702f.json', '0c786b71.json',
|
||||
'626c0bcc.json', 'aa300dc3.json', 'c62e2108.json', '0692e18c.json',
|
||||
'af22c60d.json', '992798f6.json', 'c48954c1.json', '5b526a93.json',
|
||||
'ae58858e.json', 'ff72ca3e.json', '2b01abd0.json', '7d18a6fb.json',
|
||||
'963f59bc.json', '759f3fd3.json', '7c9b52a0.json', '4852f2fa.json',
|
||||
'14754a24.json', 'c87289bb.json', '845d6e51.json', '281123b4.json',
|
||||
'79369cc6.json', '0a1d4ef5.json', '477d2879.json', '72a961c9.json',
|
||||
'67b4a34d.json', 'e5c44e8f.json', 'bf699163.json', '13713586.json',
|
||||
'27f8ce4f.json', '95a58926.json', '15696249.json', 'd2acf2cb.json',
|
||||
'140c817e.json', '1990f7a8.json', '782b5218.json', '8b28cd80.json',
|
||||
'92e50de0.json', 'e619ca6e.json', '5b6cbef5.json', '575b1a71.json',
|
||||
'66e6c45b.json', '31adaf00.json', '6ea4a07e.json', 'f0afb749.json',
|
||||
'00dbd492.json', 'b1fc8b8e.json', 'fd4b2b02.json', 'b15fca0b.json',
|
||||
'a04b2602.json', '20818e16.json', '762cd429.json', '29700607.json',
|
||||
'd5c634a2.json', 'a406ac07.json', '8ba14f53.json', '184a9768.json',
|
||||
'12997ef3.json', 'dd2401ed.json', 'f8be4b64.json', '12eac192.json',
|
||||
'31d5ba1a.json', 'b4a43f3b.json', '7ee1c6ea.json', '9b4c17c4.json',
|
||||
'981571dc.json', '93b4f4b3.json', '9caba7c3.json', '891232d6.json',
|
||||
'85fa5666.json', '0e671a1a.json', '73ccf9c2.json', '414297c0.json',
|
||||
'e872b94a.json', '99306f82.json', '3979b1a8.json', '2753e76c.json',
|
||||
'1c0d0a4b.json', '292dd178.json', 'cd3c21df.json', '33b52de3.json',
|
||||
'ecaa0ec1.json', '896d5239.json', '1a6449f1.json', '9c1e755f.json'
|
||||
]
|
||||
|
||||
@staticmethod
|
||||
def load(path: str):
|
||||
task_file_dir = get_data_path(path)
|
||||
|
||||
dataset = []
|
||||
|
||||
task_file_name_list = os.listdir(task_file_dir)
|
||||
for task_file_name in task_file_name_list:
|
||||
if task_file_name not in ARCPrizeDataset.task_file_names:
|
||||
continue
|
||||
with open(os.path.join(task_file_dir, task_file_name),
|
||||
'r') as file:
|
||||
task = json.load(file)
|
||||
task = {
|
||||
'training_data': task['train'],
|
||||
'input_test_data': task['test'][0]['input'],
|
||||
'output_test_data': task['test'][0]['output']
|
||||
}
|
||||
dataset.append(task)
|
||||
|
||||
return Dataset.from_list(dataset)
|
||||
|
||||
|
||||
class ARCPrizeEvaluator(BaseEvaluator):
|
||||
|
||||
def score(self, predictions: List[str],
|
||||
references: List[List[int]]) -> Dict:
|
||||
accuracy = []
|
||||
details = []
|
||||
for pred, refer in zip(map(extract_solution, predictions), references):
|
||||
is_correct, correct_percentage = compare_solutions_with_padding(
|
||||
pred, refer, pad_value=-1)
|
||||
details.append({
|
||||
'solved': True if is_correct else False,
|
||||
'correct_percentage': correct_percentage,
|
||||
'generated_solution': pred
|
||||
})
|
||||
accuracy.append(1 if is_correct else 0)
|
||||
|
||||
return {'accuracy': np.mean(accuracy), 'details': details}
|
||||
|
||||
|
||||
def extract_solution(text):
|
||||
try:
|
||||
# Find the part of the text that looks like a nested list
|
||||
start = text.index('[[')
|
||||
end = text.index(']]', start) + 2
|
||||
array_str = text[start:end]
|
||||
|
||||
# Use ast.literal_eval to safely evaluate the
|
||||
# string as a Python expression
|
||||
array = ast.literal_eval(array_str)
|
||||
# Check if the result is a list of lists
|
||||
if all(isinstance(i, list) for i in array):
|
||||
if all(all(isinstance(i, int) for i in j) for j in array):
|
||||
return array
|
||||
else:
|
||||
return [[0]]
|
||||
else:
|
||||
return [[0]]
|
||||
except (ValueError, SyntaxError):
|
||||
return [[0]]
|
||||
|
||||
|
||||
def pad_array_with_value(array, target_shape, pad_value):
|
||||
padded_array = np.full(target_shape, pad_value, dtype=int)
|
||||
for i in range(len(array)):
|
||||
padded_array[i, :len(array[i])] = array[i]
|
||||
return padded_array
|
||||
|
||||
|
||||
def compare_solutions_with_padding(generated_output: List[int],
|
||||
correct_output: List[int],
|
||||
pad_value=-1):
|
||||
max_rows = max(len(generated_output), len(correct_output))
|
||||
max_cols = max(max(map(len, generated_output)),
|
||||
max(map(len, correct_output)))
|
||||
target_shape = (max_rows, max_cols)
|
||||
|
||||
padded_generated = pad_array_with_value(generated_output, target_shape,
|
||||
pad_value)
|
||||
padded_correct = pad_array_with_value(correct_output, target_shape,
|
||||
pad_value)
|
||||
|
||||
total_pixels = max_rows * max_cols
|
||||
correct_pixels = np.sum((padded_generated == padded_correct)
|
||||
& (padded_generated != pad_value)
|
||||
& (padded_correct != pad_value))
|
||||
correct_percentage = (correct_pixels / total_pixels) * 100
|
||||
|
||||
is_correct = (correct_pixels == total_pixels)
|
||||
|
||||
return is_correct, correct_percentage
|
||||
@ -63,6 +63,35 @@ class CompassBenchObjectiveV1_3(BaseDataset):
|
||||
return dataset
|
||||
|
||||
|
||||
@LOAD_DATASET.register_module()
|
||||
class CompassBenchObjectiveMath(BaseDataset):
|
||||
|
||||
@staticmethod
|
||||
def load(path: str):
|
||||
with open(path, 'r') as infile:
|
||||
data = [json.loads(line) for line in infile]
|
||||
for idx in range(len(data)):
|
||||
item = data[idx]
|
||||
prefix = ''
|
||||
if item.get('question_type',
|
||||
None) and item['question_type'] in [
|
||||
'multiple-answer', '多选题'
|
||||
]:
|
||||
if '_en_' in path:
|
||||
prefix = 'This question may has multiple answers, \
|
||||
please select all correct answers. like this: A, B, C as your final answer\n'
|
||||
|
||||
else:
|
||||
prefix = '这道题可能有多个正确答案,请选择所有正确的答案,\
|
||||
例如:A, B, C 作为你的最终答案\n'
|
||||
|
||||
if item.get('options', None) and len(item['options']) != 0:
|
||||
item['question'] = prefix + item[
|
||||
'question'] + '\n' + get_number(item['options'])
|
||||
dataset = Dataset.from_list(data)
|
||||
return dataset
|
||||
|
||||
|
||||
@TEXT_POSTPROCESSORS.register_module()
|
||||
def compassbench_objective_v1_3_postprocess(text: str, name) -> str:
|
||||
split = False
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user