mirror of
https://github.com/open-compass/opencompass.git
synced 2025-05-30 16:03:24 +08:00
[Docs] Update README (#956)
* [Docs] Update README * Update README.md * [Docs] Update README
This commit is contained in:
parent
bdd85358cc
commit
47cb75a3f7
43
README.md
43
README.md
@ -9,6 +9,8 @@
|
||||
<!-- [](https://pypi.org/project/opencompass/) -->
|
||||
|
||||
[🌐Website](https://opencompass.org.cn/) |
|
||||
[📖CompassHub](https://hub.opencompass.org.cn/home) |
|
||||
[📊CompassRank](https://rank.opencompass.org.cn/home) |
|
||||
[📘Documentation](https://opencompass.readthedocs.io/en/latest/) |
|
||||
[🛠️Installation](https://opencompass.readthedocs.io/en/latest/get_started/installation.html) |
|
||||
[🤔Reporting Issues](https://github.com/open-compass/opencompass/issues/new/choose)
|
||||
@ -21,19 +23,16 @@ English | [简体中文](README_zh-CN.md)
|
||||
👋 join us on <a href="https://discord.gg/KKwfEbFj7U" target="_blank">Discord</a> and <a href="https://r.vansin.top/?r=opencompass" target="_blank">WeChat</a>
|
||||
</p>
|
||||
|
||||
## 📣 OpenCompass 2023 LLM Annual Leaderboard
|
||||
## 📣 OpenCompass 2.0
|
||||
|
||||
We are honored to have witnessed the tremendous progress of artificial general intelligence together with the community in the past year, and we are also very pleased that **OpenCompass** can help numerous developers and users.
|
||||
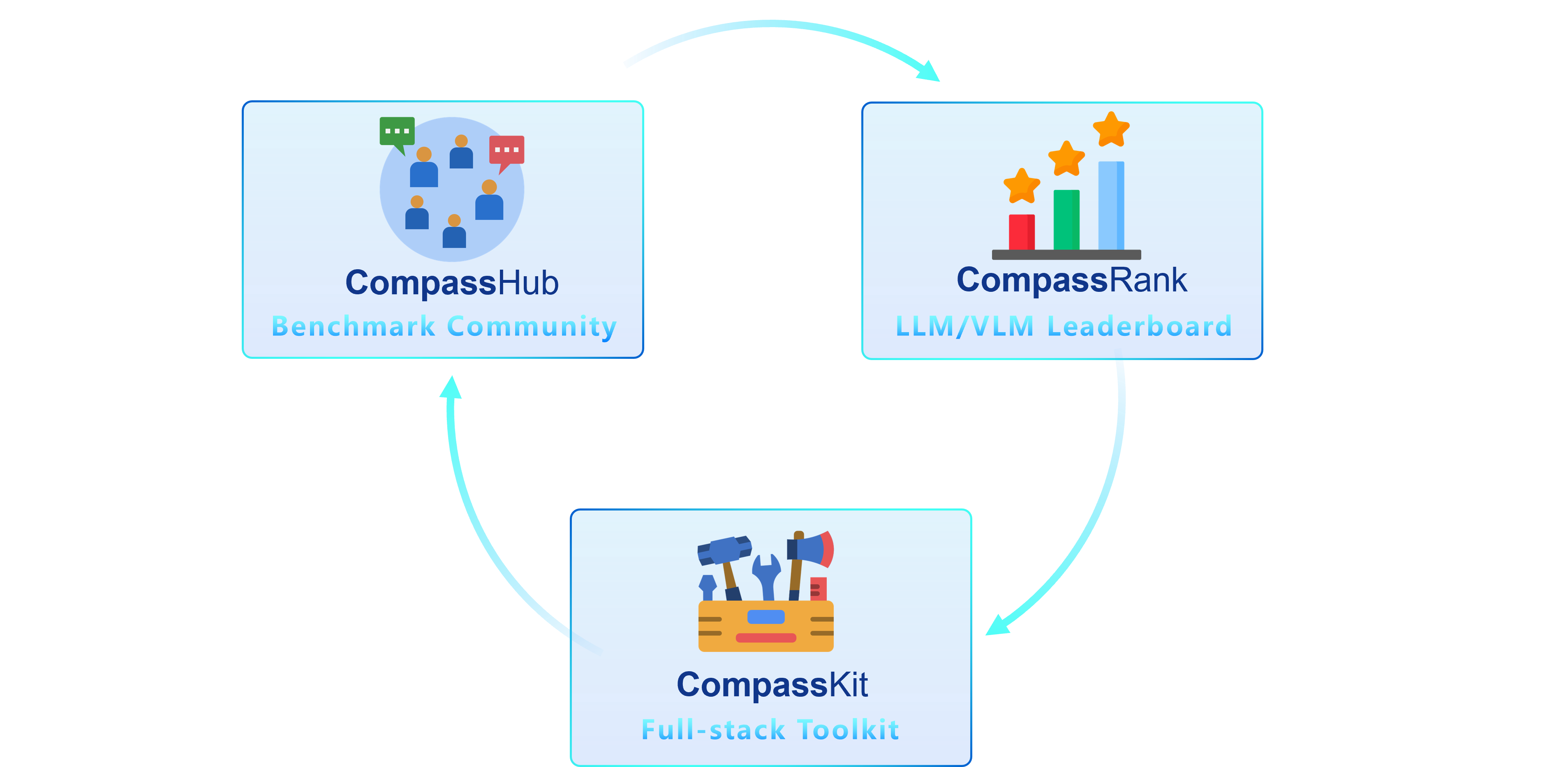
We are thrilled to introduce OpenCompass 2.0, an advanced suite featuring three key components: [CompassKit](https://github.com/open-compass), [CompassHub](https://hub.opencompass.org.cn/home), and [CompassRank](https://rank.opencompass.org.cn/home).
|
||||
|
||||
|
||||
We announce the launch of the **OpenCompass 2023 LLM Annual Leaderboard** plan. We expect to release the annual leaderboard of the LLMs in January 2024, systematically evaluating the performance of LLMs in various capabilities such as language, knowledge, reasoning, creation, long-text, and agents.
|
||||
**CompassRank** has been significantly enhanced into the leaderboards that now incorporates both open-source benchmarks and proprietary benchmarks. This upgrade allows for a more comprehensive evaluation of models across the industry.
|
||||
|
||||
At that time, we will release rankings for both open-source models and commercial API models, aiming to provide a comprehensive, objective, and neutral reference for the industry and research community.
|
||||
**CompassHub** presents a pioneering benchmark browser interface, designed to simplify and expedite the exploration and utilization of an extensive array of benchmarks for researchers and practitioners alike. To enhance the visibility of your own benchmark within the community, we warmly invite you to contribute it to CompassHub. You may initiate the submission process by clicking [here](https://hub.opencompass.org.cn/dataset-submit).
|
||||
|
||||
We sincerely invite various large models to join the OpenCompass to showcase their performance advantages in different fields. At the same time, we also welcome researchers and developers to provide valuable suggestions and contributions to jointly promote the development of the LLMs. If you have any questions or needs, please feel free to [contact us](mailto:opencompass@pjlab.org.cn). In addition, relevant evaluation contents, performance statistics, and evaluation methods will be open-source along with the leaderboard release.
|
||||
|
||||
We have provided the more details of the CompassBench 2023 in [Doc](docs/zh_cn/advanced_guides/compassbench_intro.md).
|
||||
|
||||
Let's look forward to the release of the OpenCompass 2023 LLM Annual Leaderboard!
|
||||
**CompassKit** is a powerful collection of evaluation toolkits specifically tailored for Large Language Models and Large Vision-language Models. It provides an extensive set of tools to assess and measure the performance of these complex models effectively. Welcome to try our toolkits for in your research and products.
|
||||
|
||||
## 🧭 Welcome
|
||||
|
||||
@ -52,12 +51,12 @@ Just like a compass guides us on our journey, OpenCompass will guide you through
|
||||
|
||||
## 🚀 What's New <a><img width="35" height="20" src="https://user-images.githubusercontent.com/12782558/212848161-5e783dd6-11e8-4fe0-bbba-39ffb77730be.png"></a>
|
||||
|
||||
- **\[2024.02.29\]** We supported the MT-Bench, AlpacalEval and AlignBench, more information can be found [here](https://opencompass.readthedocs.io/en/latest/advanced_guides/subjective_evaluation.html) 🔥🔥🔥.
|
||||
- **\[2024.01.30\]** We release OpenCompass 2.0. Click [CompassKit](https://github.com/open-compass), [CompassHub](https://hub.opencompass.org.cn/home), and [CompassRank](https://rank.opencompass.org.cn/home) for more information ! 🔥🔥🔥.
|
||||
- **\[2024.01.17\]** We supported the evaluation of [InternLM2](https://github.com/open-compass/opencompass/blob/main/configs/eval_internlm2_keyset.py) and [InternLM2-Chat](https://github.com/open-compass/opencompass/blob/main/configs/eval_internlm2_chat_keyset.py), InternLM2 showed extremely strong performance in these tests, welcome to try! 🔥🔥🔥.
|
||||
- **\[2024.01.17\]** We supported the needle in a haystack test with multiple needles, more information can be found [here](https://opencompass.readthedocs.io/en/latest/advanced_guides/needleinahaystack_eval.html#id8) 🔥🔥🔥.
|
||||
- **\[2023.12.28\]** We have enabled seamless evaluation of all models developed using [LLaMA2-Accessory](https://github.com/Alpha-VLLM/LLaMA2-Accessory), a powerful toolkit for comprehensive LLM development. 🔥🔥🔥.
|
||||
- **\[2023.12.22\]** We have released [T-Eval](https://github.com/open-compass/T-Eval), a step-by-step evaluation benchmark to gauge your LLMs on tool utilization. Welcome to our [Leaderboard](https://open-compass.github.io/T-Eval/leaderboard.html) for more details! 🔥🔥🔥.
|
||||
- **\[2023.12.10\]** We have released [VLMEvalKit](https://github.com/open-compass/VLMEvalKit), a toolkit for evaluating vision-language models (VLMs), currently support 20+ VLMs and 7 multi-modal benchmarks (including MMBench series).
|
||||
- **\[2023.12.10\]** We have supported Mistral AI's MoE LLM: **Mixtral-8x7B-32K**. Welcome to [MixtralKit](https://github.com/open-compass/MixtralKit) for more details about inference and evaluation.
|
||||
- **\[2023.12.28\]** We have enabled seamless evaluation of all models developed using [LLaMA2-Accessory](https://github.com/Alpha-VLLM/LLaMA2-Accessory), a powerful toolkit for comprehensive LLM development.
|
||||
- **\[2023.12.22\]** We have released [T-Eval](https://github.com/open-compass/T-Eval), a step-by-step evaluation benchmark to gauge your LLMs on tool utilization. Welcome to our [Leaderboard](https://open-compass.github.io/T-Eval/leaderboard.html) for more details!
|
||||
|
||||
> [More](docs/en/notes/news.md)
|
||||
|
||||
@ -420,10 +419,6 @@ Through the command line or configuration files, OpenCompass also supports evalu
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
## OpenCompass Ecosystem
|
||||
|
||||
<p align="right"><a href="#top">🔝Back to top</a></p>
|
||||
|
||||
## 📖 Model Support
|
||||
|
||||
<table align="center">
|
||||
@ -453,12 +448,14 @@ Through the command line or configuration files, OpenCompass also supports evalu
|
||||
- [TigerBot](https://github.com/TigerResearch/TigerBot)
|
||||
- [Qwen](https://github.com/QwenLM/Qwen)
|
||||
- [BlueLM](https://github.com/vivo-ai-lab/BlueLM)
|
||||
- [Gemma](https://huggingface.co/google/gemma-7b)
|
||||
- ...
|
||||
|
||||
</td>
|
||||
<td>
|
||||
|
||||
- OpenAI
|
||||
- Gemini
|
||||
- Claude
|
||||
- ZhipuAI(ChatGLM)
|
||||
- Baichuan
|
||||
@ -481,18 +478,18 @@ Through the command line or configuration files, OpenCompass also supports evalu
|
||||
|
||||
## 🔜 Roadmap
|
||||
|
||||
- [ ] Subjective Evaluation
|
||||
- [x] Subjective Evaluation
|
||||
- [ ] Release CompassAreana
|
||||
- [ ] Subjective evaluation dataset.
|
||||
- [x] Subjective evaluation.
|
||||
- [x] Long-context
|
||||
- [ ] Long-context evaluation with extensive datasets.
|
||||
- [x] Long-context evaluation with extensive datasets.
|
||||
- [ ] Long-context leaderboard.
|
||||
- [ ] Coding
|
||||
- [x] Coding
|
||||
- [ ] Coding evaluation leaderboard.
|
||||
- [x] Non-python language evaluation service.
|
||||
- [ ] Agent
|
||||
- [x] Agent
|
||||
- [ ] Support various agenet framework.
|
||||
- [ ] Evaluation of tool use of the LLMs.
|
||||
- [x] Evaluation of tool use of the LLMs.
|
||||
- [x] Robustness
|
||||
- [x] Support various attack method
|
||||
|
||||
|
||||
@ -8,10 +8,12 @@
|
||||
|
||||
<!-- [](https://pypi.org/project/opencompass/) -->
|
||||
|
||||
[🌐Website](https://opencompass.org.cn/) |
|
||||
[📘Documentation](https://opencompass.readthedocs.io/zh_CN/latest/index.html) |
|
||||
[🛠️Installation](https://opencompass.readthedocs.io/zh_CN/latest/get_started/installation.html) |
|
||||
[🤔Reporting Issues](https://github.com/open-compass/opencompass/issues/new/choose)
|
||||
[🌐官方网站](https://opencompass.org.cn/) |
|
||||
[📖数据集社区](https://hub.opencompass.org.cn/home) |
|
||||
[📊性能榜单](https://rank.opencompass.org.cn/home) |
|
||||
[📘文档教程](https://opencompass.readthedocs.io/zh_CN/latest/index.html) |
|
||||
[🛠️安装](https://opencompass.readthedocs.io/zh_CN/latest/get_started/installation.html) |
|
||||
[🤔报告问题](https://github.com/open-compass/opencompass/issues/new/choose)
|
||||
|
||||
[English](/README.md) | 简体中文
|
||||
|
||||
@ -21,19 +23,15 @@
|
||||
👋 加入我们的 <a href="https://discord.gg/KKwfEbFj7U" target="_blank">Discord</a> 和 <a href="https://r.vansin.top/?r=opencompass" target="_blank">微信社区</a>
|
||||
</p>
|
||||
|
||||
## 📣 2023 年度榜单计划
|
||||
## 📣 OpenCompass 2.0
|
||||
|
||||
我们有幸与社区共同见证了通用人工智能在过去一年里的巨大进展,也非常高兴OpenCompass能够帮助广大大模型开发者和使用者。
|
||||
我们很高兴发布 OpenCompass 司南 2.0 大模型评测体系,它主要由三大核心模块构建而成:[CompassKit](https://github.com/open-compass)、[CompassHub](https://hub.opencompass.org.cn/home)以及[CompassRank](https://rank.opencompass.org.cn/home)。
|
||||
|
||||
我们宣布将启动**OpenCompass 2023年度大模型榜单**发布计划。我们预计将于2024年1月发布大模型年度榜单,系统性评估大模型在语言、知识、推理、创作、长文本和智能体等多个能力维度的表现。
|
||||
**CompassRank** 系统进行了重大革新与提升,现已成为一个兼容并蓄的排行榜体系,不仅囊括了开源基准测试项目,还包含了私有基准测试。此番升级极大地拓宽了对行业内各类模型进行全面而深入测评的可能性。
|
||||
|
||||
届时,我们将发布开源模型和商业API模型能力榜单,以期为业界提供一份**全面、客观、中立**的参考。
|
||||
**CompassHub** 创新性地推出了一个基准测试资源导航平台,其设计初衷旨在简化和加快研究人员及行业从业者在多样化的基准测试库中进行搜索与利用的过程。为了让更多独具特色的基准测试成果得以在业内广泛传播和应用,我们热忱欢迎各位将自定义的基准数据贡献至CompassHub平台。只需轻点鼠标,通过访问[这里](https://hub.opencompass.org.cn/dataset-submit),即可启动提交流程。
|
||||
|
||||
我们诚挚邀请各类大模型接入OpenCompass评测体系,以展示其在各个领域的性能优势。同时,也欢迎广大研究者、开发者向我们提供宝贵的意见和建议,共同推动大模型领域的发展。如有任何问题或需求,请随时[联系我们](mailto:opencompass@pjlab.org.cn)。此外,相关评测内容,性能数据,评测方法也将随榜单发布一并开源。
|
||||
|
||||
我们提供了本次评测所使用的部分题目示例,详情请见[CompassBench 2023](docs/zh_cn/advanced_guides/compassbench_intro.md).
|
||||
|
||||
<p>让我们共同期待OpenCompass 2023年度大模型榜单的发布,期待各大模型在榜单上的精彩表现!</p>
|
||||
**CompassKit** 是一系列专为大型语言模型和大型视觉-语言模型打造的强大评估工具合集,它所提供的全面评测工具集能够有效地对这些复杂模型的功能性能进行精准测量和科学评估。在此,我们诚挚邀请您在学术研究或产品研发过程中积极尝试运用我们的工具包,以助您取得更加丰硕的研究成果和产品优化效果。
|
||||
|
||||
## 🧭 欢迎
|
||||
|
||||
@ -52,12 +50,12 @@
|
||||
|
||||
## 🚀 最新进展 <a><img width="35" height="20" src="https://user-images.githubusercontent.com/12782558/212848161-5e783dd6-11e8-4fe0-bbba-39ffb77730be.png"></a>
|
||||
|
||||
- **\[2024.02.29\]** 我们支持了MT-Bench、AlpacalEval和AlignBench,更多信息可以在[这里](https://opencompass.readthedocs.io/en/latest/advanced_guides/subjective_evaluation.html)找到 🔥🔥🔥。
|
||||
- **\[2024.01.30\]** 我们发布了OpenCompass 2.0。更多信息,请访问[CompassKit](https://github.com/open-compass)、[CompassHub](https://hub.opencompass.org.cn/home)和[CompassRank](https://rank.opencompass.org.cn/home) 🔥🔥🔥。
|
||||
- **\[2024.01.17\]** 我们支持了 [InternLM2](https://github.com/open-compass/opencompass/blob/main/configs/eval_internlm2_chat_keyset.py) 和 [InternLM2-Chat](https://github.com/open-compass/opencompass/blob/main/configs/eval_internlm2_chat_keyset.py) 的相关评测,InternLM2 在这些测试中表现出非常强劲的性能,欢迎试用!🔥🔥🔥.
|
||||
- **\[2024.01.17\]** 我们支持了多根针版本的大海捞针测试,更多信息见[这里](https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/needleinahaystack_eval.html#id8)🔥🔥🔥.
|
||||
- **\[2023.12.28\]** 我们支持了对使用[LLaMA2-Accessory](https://github.com/Alpha-VLLM/LLaMA2-Accessory)(一款强大的LLM开发工具箱)开发的所有模型的无缝评估! 🔥🔥🔥.
|
||||
- **\[2023.12.22\]** 我们开源了[T-Eval](https://github.com/open-compass/T-Eval)用于评测大语言模型工具调用能力。欢迎访问T-Eval的官方[Leaderboard](https://open-compass.github.io/T-Eval/leaderboard.html)获取更多信息! 🔥🔥🔥.
|
||||
- **\[2023.12.10\]** 我们开源了多模评测框架 [VLMEvalKit](https://github.com/open-compass/VLMEvalKit),目前已支持 20+ 个多模态大模型与包括 MMBench 系列在内的 7 个多模态评测集.
|
||||
- **\[2023.12.10\]** 我们已经支持了Mistral AI的MoE模型 **Mixtral-8x7B-32K**。欢迎查阅[MixtralKit](https://github.com/open-compass/MixtralKit)以获取更多关于推理和评测的详细信息.
|
||||
- **\[2023.12.28\]** 我们支持了对使用[LLaMA2-Accessory](https://github.com/Alpha-VLLM/LLaMA2-Accessory)(一款强大的LLM开发工具箱)开发的所有模型的无缝评估!
|
||||
- **\[2023.12.22\]** 我们开源了[T-Eval](https://github.com/open-compass/T-Eval)用于评测大语言模型工具调用能力。欢迎访问T-Eval的官方[Leaderboard](https://open-compass.github.io/T-Eval/leaderboard.html)获取更多信息!
|
||||
|
||||
> [更多](docs/zh_cn/notes/news.md)
|
||||
|
||||
@ -455,12 +453,14 @@ python run.py --datasets ceval_ppl mmlu_ppl \
|
||||
- [TigerBot](https://github.com/TigerResearch/TigerBot)
|
||||
- [Qwen](https://github.com/QwenLM/Qwen)
|
||||
- [BlueLM](https://github.com/vivo-ai-lab/BlueLM)
|
||||
- [Gemma](https://huggingface.co/google/gemma-7b)
|
||||
- ……
|
||||
|
||||
</td>
|
||||
<td>
|
||||
|
||||
- OpenAI
|
||||
- Gemini
|
||||
- Claude
|
||||
- ZhipuAI(ChatGLM)
|
||||
- Baichuan
|
||||
@ -483,18 +483,18 @@ python run.py --datasets ceval_ppl mmlu_ppl \
|
||||
|
||||
## 🔜 路线图
|
||||
|
||||
- [ ] 主观评测
|
||||
- [ ] 发布主观评测榜单
|
||||
- [x] 主观评测
|
||||
- [x] 发布主观评测榜单
|
||||
- [ ] 发布主观评测数据集
|
||||
- [x] 长文本
|
||||
- [ ] 支持广泛的长文本评测集
|
||||
- [x] 支持广泛的长文本评测集
|
||||
- [ ] 发布长文本评测榜单
|
||||
- [ ] 代码能力
|
||||
- [x] 代码能力
|
||||
- [ ] 发布代码能力评测榜单
|
||||
- [x] 提供非Python语言的评测服务
|
||||
- [ ] 智能体
|
||||
- [x] 智能体
|
||||
- [ ] 支持丰富的智能体方案
|
||||
- [ ] 提供智能体评测榜单
|
||||
- [x] 提供智能体评测榜单
|
||||
- [x] 鲁棒性
|
||||
- [x] 支持各类攻击方法
|
||||
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# News
|
||||
|
||||
- **\[2023.12.10\]** We have released [VLMEvalKit](https://github.com/open-compass/VLMEvalKit), a toolkit for evaluating vision-language models (VLMs), currently support 20+ VLMs and 7 multi-modal benchmarks (including MMBench series).
|
||||
- **\[2023.12.10\]** We have supported Mistral AI's MoE LLM: **Mixtral-8x7B-32K**. Welcome to [MixtralKit](https://github.com/open-compass/MixtralKit) for more details about inference and evaluation.
|
||||
- **\[2023.11.22\]** We have supported many API-based models, include **Baidu, ByteDance, Huawei, 360**. Welcome to [Models](https://opencompass.readthedocs.io/en/latest/user_guides/models.html) section for more details.
|
||||
- **\[2023.11.20\]** Thanks [helloyongyang](https://github.com/helloyongyang) for supporting the evaluation with [LightLLM](https://github.com/ModelTC/lightllm) as backent. Welcome to [Evaluation With LightLLM](https://opencompass.readthedocs.io/en/latest/advanced_guides/evaluation_lightllm.html) for more details.
|
||||
- **\[2023.11.13\]** We are delighted to announce the release of OpenCompass v0.1.8. This version enables local loading of evaluation benchmarks, thereby eliminating the need for an internet connection. Please note that with this update, **you must re-download all evaluation datasets** to ensure accurate and up-to-date results.
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# 新闻
|
||||
|
||||
- **\[2023.12.10\]** 我们开源了多模评测框架 [VLMEvalKit](https://github.com/open-compass/VLMEvalKit),目前已支持 20+ 个多模态大模型与包括 MMBench 系列在内的 7 个多模态评测集.
|
||||
- **\[2023.12.10\]** 我们已经支持了Mistral AI的MoE模型 **Mixtral-8x7B-32K**。欢迎查阅[MixtralKit](https://github.com/open-compass/MixtralKit)以获取更多关于推理和评测的详细信息.
|
||||
- **\[2023.11.22\]** 我们已经支持了多个于API的模型,包括**百度、字节跳动、华为、360**。欢迎查阅[模型](https://opencompass.readthedocs.io/en/latest/user_guides/models.html)部分以获取更多详细信息。
|
||||
- **\[2023.11.20\]** 感谢[helloyongyang](https://github.com/helloyongyang)支持使用[LightLLM](https://github.com/ModelTC/lightllm)作为后端进行评估。欢迎查阅[使用LightLLM进行评估](https://opencompass.readthedocs.io/en/latest/advanced_guides/evaluation_lightllm.html)以获取更多详细信息。
|
||||
- **\[2023.11.13\]** 我们很高兴地宣布发布 OpenCompass v0.1.8 版本。此版本支持本地加载评估基准,从而无需连接互联网。请注意,随着此更新的发布,**您需要重新下载所有评估数据集**,以确保结果准确且最新。
|
||||
|
||||
Loading…
Reference in New Issue
Block a user