mirror of
https://github.com/open-compass/opencompass.git
synced 2025-05-30 16:03:24 +08:00
[Docs] Add intro figure to README (#413)
* [Docs] Add intro figure to README * update
This commit is contained in:
parent
bd50bad8b5
commit
3e980a9737
@ -40,15 +40,13 @@ Just like a compass guides us on our journey, OpenCompass will guide you through
|
||||
- **\[2023.09.02\]** We have supported the evaluation of [Qwen-VL](https://github.com/QwenLM/Qwen-VL) in OpenCompass.
|
||||
- **\[2023.08.25\]** [**TigerBot**](https://github.com/TigerResearch/TigerBot) team adpots OpenCompass to evaluate their models systematically. We deeply appreciate the community's dedication to transparency and reproducibility in LLM evaluation.
|
||||
- **\[2023.08.21\]** [**Lagent**](https://github.com/InternLM/lagent) has been released, which is a lightweight framework for building LLM-based agents. We are working with Lagent team to support the evaluation of general tool-use capability, stay tuned!
|
||||
- **\[2023.08.18\]** We have supported evaluation for **multi-modality learning**, include **MMBench, SEED-Bench, COCO-Caption, Flickr-30K, OCR-VQA, ScienceQA** and so on. Leaderboard is on the road. Feel free to try multi-modality evaluation with OpenCompass !
|
||||
- **\[2023.08.18\]** [Dataset card](https://opencompass.org.cn/dataset-detail/MMLU) is now online. Welcome new evaluation benchmark OpenCompass !
|
||||
- **\[2023.08.11\]** [Model comparison](https://opencompass.org.cn/model-compare/GPT-4,ChatGPT,LLaMA-2-70B,LLaMA-65B) is now online. We hope this feature offers deeper insights!
|
||||
- **\[2023.08.11\]** We have supported [LEval](https://github.com/OpenLMLab/LEval).
|
||||
|
||||
> [More](docs/en/notes/news.md)
|
||||
|
||||
## ✨ Introduction
|
||||
|
||||
|
||||
|
||||
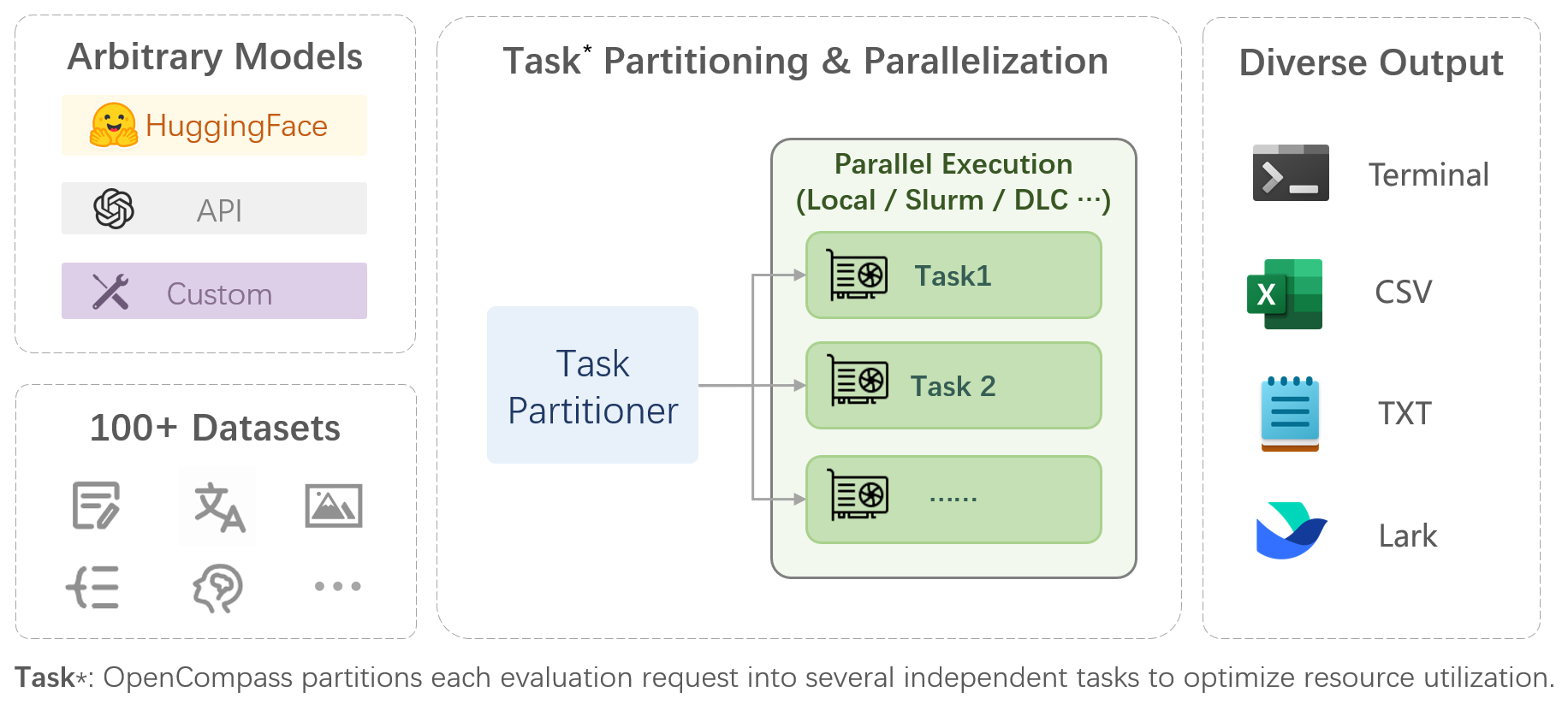
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features includes:
|
||||
|
||||
- **Comprehensive support for models and datasets**: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 50+ datasets with about 300,000 questions, comprehensively evaluating the capabilities of the models in five dimensions.
|
||||
|
||||
@ -40,15 +40,13 @@
|
||||
- **\[2023.09.02\]** 我们加入了[Qwen-VL](https://github.com/QwenLM/Qwen-VL)的评测支持。
|
||||
- **\[2023.08.25\]** 欢迎 [**TigerBot**](https://github.com/TigerResearch/TigerBot) 团队采用OpenCompass对模型进行系统评估。我们非常感谢社区在提升LLM评估的透明度和可复现性上所做的努力。
|
||||
- **\[2023.08.21\]** [**Lagent**](https://github.com/InternLM/lagent) 正式发布,它是一个轻量级、开源的基于大语言模型的智能体(agent)框架。我们正与Lagent团队紧密合作,推进支持基于Lagent的大模型工具能力评测 !
|
||||
- **\[2023.08.18\]** OpenCompass现已支持**多模态评测**,支持10+多模态评测数据集,包括 **MMBench, SEED-Bench, COCO-Caption, Flickr-30K, OCR-VQA, ScienceQA** 等. 多模态评测榜单即将上线,敬请期待!
|
||||
- **\[2023.08.18\]** [数据集页面](https://opencompass.org.cn/dataset-detail/MMLU) 现已在OpenCompass官网上线,欢迎更多社区评测数据集加入OpenCompass !
|
||||
- **\[2023.08.11\]** 官网榜单上新增了[模型对比](https://opencompass.org.cn/model-compare/GPT-4,ChatGPT,LLaMA-2-70B,LLaMA-65B)功能,希望该功能可以协助提供更多发现!
|
||||
- **\[2023.08.11\]** 新增了 [LEval](https://github.com/OpenLMLab/LEval) 评测支持.
|
||||
|
||||
> [更多](docs/zh_cn/notes/news.md)
|
||||
|
||||
## ✨ 介绍
|
||||
|
||||

|
||||
|
||||
OpenCompass 是面向大模型评测的一站式平台。其主要特点如下:
|
||||
|
||||
- **开源可复现**:提供公平、公开、可复现的大模型评测方案
|
||||
|
||||
@ -1,5 +1,9 @@
|
||||
# News
|
||||
|
||||
- **\[2023.08.18\]** We have supported evaluation for **multi-modality learning**, include **MMBench, SEED-Bench, COCO-Caption, Flickr-30K, OCR-VQA, ScienceQA** and so on. Leaderboard is on the road. Feel free to try multi-modality evaluation with OpenCompass !
|
||||
- **\[2023.08.18\]** [Dataset card](https://opencompass.org.cn/dataset-detail/MMLU) is now online. Welcome new evaluation benchmark OpenCompass !
|
||||
- **\[2023.08.11\]** [Model comparison](https://opencompass.org.cn/model-compare/GPT-4,ChatGPT,LLaMA-2-70B,LLaMA-65B) is now online. We hope this feature offers deeper insights!
|
||||
- **\[2023.08.11\]** We have supported [LEval](https://github.com/OpenLMLab/LEval).
|
||||
- **\[2023.08.10\]** OpenCompass is compatible with [LMDeploy](https://github.com/InternLM/lmdeploy). Now you can follow this [instruction](https://opencompass.readthedocs.io/en/latest/advanced_guides/evaluation_turbomind.html#) to evaluate the accelerated models provide by the **Turbomind**.
|
||||
- **\[2023.08.10\]** We have supported [Qwen-7B](https://github.com/QwenLM/Qwen-7B) and [XVERSE-13B](https://github.com/xverse-ai/XVERSE-13B) ! Go to our [leaderboard](https://opencompass.org.cn/leaderboard-llm) for more results! More models are welcome to join OpenCompass.
|
||||
- **\[2023.08.09\]** Several new datasets(**CMMLU, TydiQA, SQuAD2.0, DROP**) are updated on our [leaderboard](https://opencompass.org.cn/leaderboard-llm)! More datasets are welcomed to join OpenCompass.
|
||||
|
||||
@ -1,5 +1,9 @@
|
||||
# 新闻
|
||||
|
||||
- **\[2023.08.18\]** OpenCompass现已支持**多模态评测**,支持10+多模态评测数据集,包括 **MMBench, SEED-Bench, COCO-Caption, Flickr-30K, OCR-VQA, ScienceQA** 等. 多模态评测榜单即将上线,敬请期待!
|
||||
- **\[2023.08.18\]** [数据集页面](https://opencompass.org.cn/dataset-detail/MMLU) 现已在OpenCompass官网上线,欢迎更多社区评测数据集加入OpenCompass !
|
||||
- **\[2023.08.11\]** 官网榜单上新增了[模型对比](https://opencompass.org.cn/model-compare/GPT-4,ChatGPT,LLaMA-2-70B,LLaMA-65B)功能,希望该功能可以协助提供更多发现!
|
||||
- **\[2023.08.11\]** 新增了 [LEval](https://github.com/OpenLMLab/LEval) 评测支持.
|
||||
- **\[2023.08.10\]** OpenCompass 现已适配 [LMDeploy](https://github.com/InternLM/lmdeploy). 请参考 [评测指南](https://opencompass.readthedocs.io/zh_CN/latest/advanced_guides/evaluation_turbomind.html) 对 **Turbomind** 加速后的模型进行评估.
|
||||
- **\[2023.08.10\]** [Qwen-7B](https://github.com/QwenLM/Qwen-7B) 和 [XVERSE-13B](https://github.com/xverse-ai/XVERSE-13B)的评测结果已更新在 OpenCompass [大语言模型评测榜单](https://opencompass.org.cn/leaderboard-llm)!
|
||||
- **\[2023.08.09\]** 更新更多评测数据集(**CMMLU, TydiQA, SQuAD2.0, DROP**) ,请登录 [大语言模型评测榜单](https://opencompass.org.cn/leaderboard-llm) 查看更多结果! 欢迎添加你的评测数据集到OpenCompass.
|
||||
|
||||
Loading…
Reference in New Issue
Block a user